![]()
![]()
![]()
![]()
When working in a multi-character set environment, character set conversion issues can occur and it can be difficult to determine where the conversion issue occurred. When encountering character set conversion issues for client APIs, examine the database and connection options and properties that control character set conversion.
There are two categories into which conversion issues can be placed. The first involves sending data in the wrong format to the client API. Although this cannot happen with Unicode APIs, it is possible with all other client APIs, and results in garbage data.
The second category of issue involves a character that does not have an equivalent in the final character set, or in one of the intermediate character sets. In this case, a substitution character is used. This is called lossy conversion and can happen with any client API. You can avoid lossy conversions by configuring the database to use UTF-8 for the database character set. See Lossy conversion and substitution characters.
 Option and property settings that impact character set conversion See also Client API and points of character set conversion
Option and property settings that impact character set conversion See also Client API and points of character set conversionThe following diagram shows the possible locations of character set conversion when client APIs interact with the database server.
The black stars in the diagram indicate a location where character set conversion can take place. The numbers in the diagram correspond to additional notes located after the diagram.
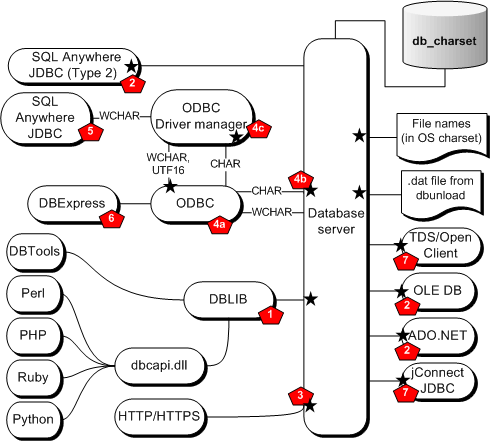
1 - DBLIB DBLIB CHAR and NCHAR character sets default to the client operating system character set. The CHAR character set is used for all string data except BINARY and NCHAR. The NCHAR character set is used for NCHAR typed host variables and host parameters (these are not available from the DBTools or DBCAPI interfaces). The database server performs all character set conversion.
You can set the CHAR character set and the NCHAR character set using the CharSet connection parameter and the db_change_nchar_charset function, respectively. See CharSet (CS) connection parameter and db_change_nchar_charset function.
2 - Unicode APIs With Unicode APIs, a driver uses the Unicode UTF-16 encoding for character data, and converts Unicode data to/from the database character set. The driver converts Unicode host parameters to the NCHAR character set (UTF-8) before sending them to the database server. Result set columns that are described as NCHAR are fetched in the NCHAR character set (UTF-8) and converted to Unicode after they are received. Setting the CharSet connection parameter is not recommended because it can result in a lossy conversion. See Lossy conversion and substitution characters.
3 - HTTP/HTTPS HTTP services (SQL Anywhere as the server): For HTTP services, there are two types of request: URL-encoded or multipart/form-data requests.
URL-encoded Requests take the form of application/x-www-form-urlencoded where variables are passed as key/value pairs. The database server automatically decodes %-encoded data (UTF-8 or database character set) and translates the key/value pairs into the database character set. Processed values can be extracted using the HTTP_VARIABLE function where the @BINARY or @TRANSPORT attributes can be used to return a value that is %-decoded but not character set translated, or the raw HTTP (transport) value, respectively.
Multipart/form-data Requests are considered to be binary—that is, using attributes @BINARY or @TRANSPORT would return identical values.
Character set conversion of an HTTP service response is controlled by the CharsetConversion and AcceptCharset HTTP options, which you can set using the sa_set_http_option system procedure. See sa_set_http_option system procedure.
Other settings that can impact character set conversion for requests and responses are the Accept-Charset header, which is used to specify the preferred character sets, and the Content-Type header, which is used to identify the character set of the content.
HTTP stored procedures (SQL Anywhere as the client): For HTTP stored procedures, CHAR data is sent in the database character set. If any parameter is an NCHAR type, then all data is sent as UTF-8 (all CHAR parameters are translated to UTF-8). The request sends an Accept-Charset HTTP header identifying the database character set as the preferred character set. UTF-8 is always included in the list of preferred character sets. If the response specifies a character set in its Content-Type header that is not the database character set, then the client translates the response into the database character set.
4a - ODBC with Unicode entry points If an ODBC application uses the Unicode entry points, it is considered a Unicode client API. WCHAR data is handled in the same way it is handled for Unicode APIs. If an ODBC application uses the Unicode entry points and CHAR (ANSI) data, the data is assumed to be in the database character set. Mixing CHAR and WCHAR data in the same application is not recommended.
4b - ODBC with ANSI entry points If an ODBC application uses the ANSI entry points, it is considered an ANSI client API. The CHAR character set defaults to the client operating system character set. The CHAR character set can be changed using the CharSet connection parameter. See CharSet (CS) connection parameter.
Any conversion of ANSI data is done by the database server. Fetching into WCHAR host variables can result in a lossy conversion for CHAR data on the database server. Mixing CHAR and WCHAR data in an application is not recommended.
4c - ODBC driver managers Some ODBC driver managers convert all CHAR data to WCHAR data and then call the Unicode entry points.
5 - SQL Anywhere JDBC driver The SQL Anywhere JDBC driver does not perform character set conversion and uses the Unicode entry points and WCHAR types of the ODBC driver. This is the same case as described for ODBC with Unicode entry points.
6 - Borland DBExpress The Borland DBExpress driver uses ODBC as an ANSI client API. The CHAR character set defaults to the client operating system character set. While you can change this using the CharSet connection parameter, it is not recommended because it can result in incorrect data.
7 - TDS clients TDS clients such as Sybase Open Client and jConnect negotiate with the database server at connect time and prefer that character set conversion take place on the client. During the negotiation, the database server is instructed not to perform character set conversion.
See also |
Discuss this page in DocCommentXchange.
|
Copyright © 2012, iAnywhere Solutions, Inc. - SQL Anywhere 12.0.1 |