![]()
![]()
![]()
![]()
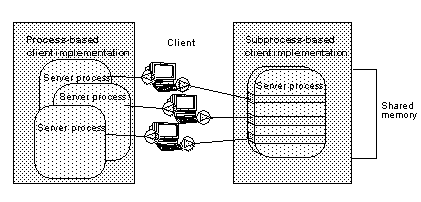
Adaptive Server client tasks are implemented as subprocesses, or “lightweight processes,” instead of operating system processes. Subprocesses use only a small fraction of the resources that processes use.
Multiple processes executing concurrently require more memory and CPU time than multiple subprocesses. Processes also require operating system resources to switch context from one process to the next.
Using subprocesses eliminates most of the overhead of paging, context switching, locking, and other operating system functions associated with a one-process-per-connection architecture. Subprocesses require no operating system resources after they are launched, and they can share many system resources and structures.
Figure 3-1 illustrates the difference in system resources required by client connections implemented as processes and client connections implemented as subprocesses. Subprocesses exist and operate within a single instance of the executing program process and its address space in shared memory.
Figure 3-1: Process versus subprocess architecture
To give Adaptive Server the maximum amount of processing power, run only essential non-Adaptive Server processes on the database machine.
