![]()
![]()
![]()
![]()
Covering matching index scans lets you skip the last read for each row returned by the query, the read that fetches the data page.
For point queries that return only a single row, the query’s performance gain is slight— just one page.
For range queries, the performance gain is larger, since the covering index saves one read for each row returned by the query.
For a covering matching index scan to be used, the index must contain all columns named in the query. In addition, the columns in the where clauses of the query must include the leading column of the columns in the index.
For example, for an index on columns A, B, C, and D, the following sets can perform matching scans: A, AB, ABC, AC, ACD, ABD, AD, and ABCD. The columns B, BC, BCD, BD, C, CD, or D do not include the leading column and can be used only for nonmatching scans.
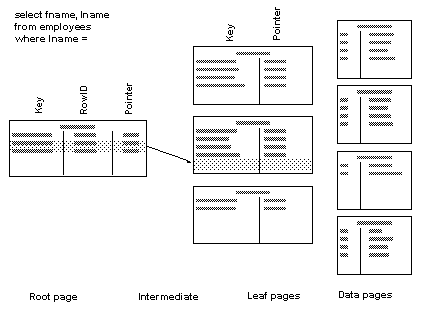
When doing a matching index scan, Adaptive Server uses standard index access methods to move from the root of the index to the nonclustered leaf page that contains the first row.
In Figure 5-11, the nonclustered index on lname, fname covers the query. The where clause includes the leading column, and all columns in the select list are included in the index, so the data page need not be accessed.
Figure 5-11: Matching index access does not have to read the data row