![]()
![]()
![]()
![]()
Adaptive Server uses syspartitions to find the root page to select a particular column (for example, a last name) using a clustered index (in versions earlier than 15.0, Adaptive Server used sysindexes). Adaptive Server examines the values on the root page and then follows page pointers, performing a binary search on each page it accesses as it traverses the index.
Figure 5-1: Selecting a row using a clustered index, allpages-locked table
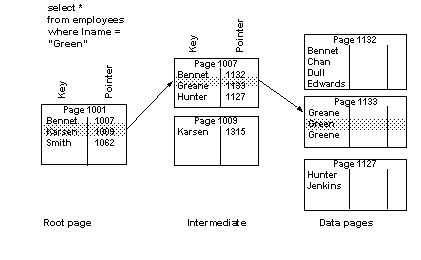
In Figure 5-1, the root level page, “Green” is greater than “Bennet,” but less than Karsen, so the pointer for “Bennet” is followed to page 1007. On page 1007, “Green” is greater than “Greane,” but less than “Hunter,” so the pointer to page 1133 is followed to the data page, where the row is located and returned to the user.
This retrieval using the clustered index requires one read for each of the:
Root level of the index
Intermediate level
Data page
These reads may come either from cache or from disk. On tables that are frequently used, the higher levels of the indexes are often found in cache, with lower levels and data pages being read from disk.
