![]()
![]()
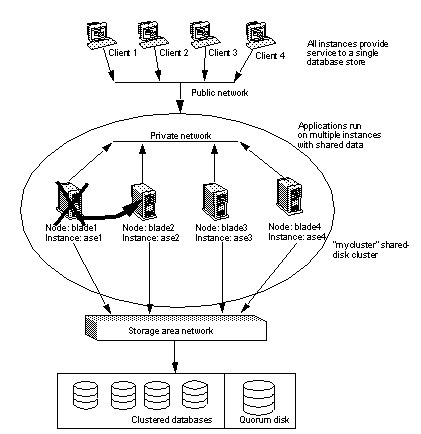
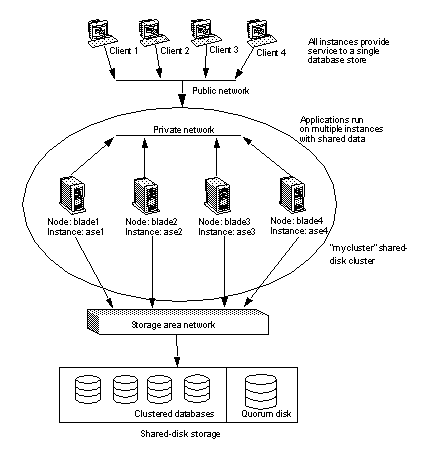
The Cluster Edition allows you to configure multiple Adaptive Servers to run as a shared-disk cluster. Multiple machines connect to a shared set of disks and a high-speed private interconnection (for example, a gigabit ethernet), allowing Adaptive Server to “scale” using multiple physical and logical hosts.
In the cluster environment, each machine is referred to as a node and each Adaptive Server as an instance. Connected instances form a cluster, working together to manage a single set of databases on the shared disks. In each case, the instances present as a single system, with all data accessible from any instance. The Cluster Edition assigns SPIDs that are unique to the cluster, so the SPID identifies a single process across all instances in the cluster.
In the clustered system shown in Figure 1-1, clients connect to a shared-disk cluster named “mycluster,” which includes the “ase1”, “ase2”, “ase3”, and “ase4” instances running on machines “blade1”, “blade2”, “blade3”, and “blade4”, respectively. In this example, a single instance resides on each node.
Figure 1-1: Key cluster-aware components
If one cluster member fails, its workload can be transferred to surviving cluster members. For example, if “ase1” fails, clients connected to that instance can fail over to any of the remaining active instances. See Figure 1-2.
![]() The Cluster Edition can handle multiple failures if
they do not happen concurrently, and can recover fully from the
initial failure before a subsequent failure occurs.
The Cluster Edition can handle multiple failures if
they do not happen concurrently, and can recover fully from the
initial failure before a subsequent failure occurs.
Figure 1-2: How the cluster handles failure