![]()
![]()
![]()
![]()
This section discusses the attribute-insensitive operations, which include scans (serial and parallel), scalar aggregations, and union alls.
For horizontal parallelism, either at least one of the tables in the query must be partitioned, or the configuration parameter max repartition degree must be greater than 1. If max repartition degree is set to 1, Adaptive Server uses the number of online engines as a hint. When Adaptive Server runs horizontal parallelism, it runs multiple versions of one or more operators in parallel. Each clone of an operator works on its partition, which can be statically created or dynamically built at execution.
The following example below shows the serial execution of a query where the table RA2 is scanned using the table scan operator. The result of this operation is routed to the emit operator, which forwards the result to the client.
select * from RA2
QUERY PLAN FOR STATEMENT 1 (at line 1). 1 operator(s) under root The type of query is SELECT. ROOT:EMIT Operator |SCAN Operator | FROM TABLE | RA2 | Table Scan. | Forward Scan. | Positioning at start of table. | Using I/O Size 2 Kbytes for data pages. | With LRU Buffer Replacement Strategy for data pages.
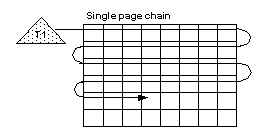
In versions earlier than 15.0, Adaptive Server did not try to scan an unpartitioned table in parallel using a hash-based scan unless a force option was used. Figure 5-4 shows a scan of an allpages-locked table executed in serial mode by a single task T1. The task follows the page chain of the table to read each page, while doing physical I/O if the needed pages are not in the cache.
Figure 5-4: Serial task scans data pages
You can force a parallel table scan of an unpartitioned table using the Adaptive Server force option. In this case, Adaptive Server uses a hash-based scan.
Figure 5-5 shows how three worker processes divide the work of accessing data pages from an allpages-locked table during a hash-based table scan. Each worker process performs a logical I/O on every page, but each process examines rows on one-third of the pages, as indicated by differently shaded lines. Hash-based table scans are used only if the user forces a parallel degree. See “Partition skew”.
With one engine, the query still benefits from parallel access because one work process can execute while others wait for I/O. If there are multiple engines, some of the worker processes can be running simultaneously.
Figure 5-5: Multiple worker processes scans unpartitioned table
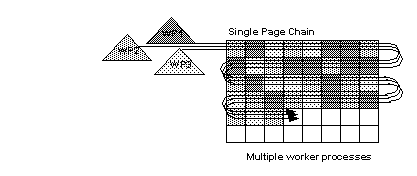
Hash-based scans increase the logical I/O for the scan, since each worker process must access each page to hash on the page ID. For a data-only-locked table, hash-based scans hash either on the extent ID or the allocation page ID, so that only a single worker process scans a page and logical I/O does not increase.
If you partition this table as follows:
alter table RA2 partition by range(a1, a2) (p1 values <= (500,100), p2 values <= (1000, 2000))
With the following query, Adaptive Server may choose a parallel scan of the table. Parallel scan is chosen only if there are sufficient pages to scan and the partition sizes are similar enough that the query will benefit from parallelism.
select * from RA2 QUERY PLAN FOR STATEMENT 1 (at line 1). Executed in parallel by coordinating process and 2 worker processes. 3 operator(s) under root The type of query is SELECT. ROOT:EMIT Operator |EXCHANGE Operator (Merged) |Executed in parallel by 2 Producer and 1 Consumer processes. | | |EXCHANGE:EMIT Operator | | | | |SCAN Operator | | | FROM TABLE | | | RA2 | | | Table Scan. | | | Forward Scan. | | | Positioning at start of table. | | | Executed in parallel with a 2-way partition scan. | | | Using I/O Size 2 Kbytes for data pages. | | | With LRU Buffer Replacement Strategy for data pages.
After partitioning the table, showplan output includes two additional operators, exchange and exchange:emit. This query includes two worker processes, each of which scans a given partition and passes the data to the exchange:emit operator, as illustrated in Figure 5-1.
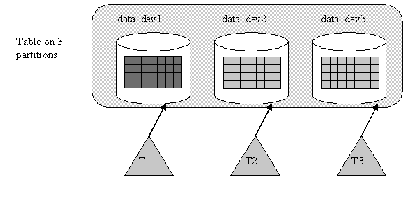
Figure 5-6 shows how a query scans a table that has three partitions on three physical disks. With a single engine, this query can benefit from parallel processing because one worker process can execute while others sleep, waiting for I/O or waiting for locks held by other processes to be released. If multiple engines are available, the worker processes can run simultaneously on multiple engines. Such a configuration can perform extremely well.
Figure 5-6: Multiple worker processes access multiple partitions
Indexes, like tables, can be partitioned or unpartitioned. Local indexes inherit the partitioning strategy of the table. Each local index partition scans data in only one partition. Global indexes have a different partitioning strategy from the base table; they reference one or more partitions.
Adaptive Server supports global indexes that are nonclustered and unpartitioned for all table partitioning strategies. Global indexes are supported for compatibility with Adaptive Server versions earlier than 15.0; they are also useful in OLTP environments. The index and the data partitions can reside on the same or different storage areas.
To create an unpartitioned global nonclustered index on table RA2, which is partitioned by range, enter:
create index RA2_NC1 on RA2(a3)
This query has a predicate that uses the index key of a3:
select * from RA2 where a3 > 300
QUERY PLAN FOR STATEMENT 1 (at line 1). . . . . . . . . . . . . . . The type of query is SELECT. ROOT:EMIT Operator |EXCHANGE Operator (Merged) |Executed in parallel by 3 Producer and 1 Consumer processes. | | |EXCHANGE:EMIT Operator | | | | |SCAN Operator | | | FROM TABLE | | | RA2 | | | Index : RA2_NC1 | | | Forward Scan. | | | Positioning by key. | | | Keys are: | | | a3 ASC | | | Executed in parallel with a 3-way hash scan. | | | Using I/O Size 2 Kbytes for index leaf pages. | | | With LRU Buffer Replacement Strategy for index leaf pages. | | | Using I/O Size 2 Kbytes for data pages. | | | With LRU Buffer Replacement Strategy for data pages.
Adaptive Server uses an index scan using the index RA2_NC1 using three producer threads spawned by the exchange operator. Each producer thread scans all qualifying leaf pages and uses a hashing algorithm on the row ID of the qualifying data and accesses the data pages to which it belongs. The parallelism in this case is exhibited at the data page level.
Figure 5-7: Hash-based parallel scan of global nonclustered index
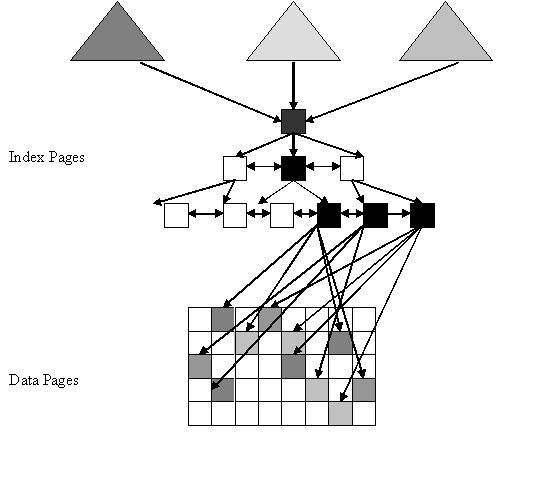
Legend for Figure 5-7:

If the query does not need to access the data page, then it does not execute in parallel. However, the partitioning columns must be added to the query; therefore, it becomes a noncovered scan:
select a3 from RA2 where a3 > 300
QUERY PLAN FOR STATEMENT 1 (at line 1). Executed in parallel by coordinating process and 2 worker processes.
3 operator(s) under root The type of query is SELECT. ROOT:EMIT Operator |EXCHANGE Operator (Merged) |Executed in parallel by 2 Producer and 1 Consumer processes. | | |EXCHANGE:EMIT Operator | | | | |SCAN Operator | | | FROM TABLE | | | RA2 | | | Index : RA2_NC1 | | | Forward Scan. | | | Positioning by key. | | | Keys are: | | | a3 ASC | | | Executed in parallel with a 2-way hash scan. | | | Using I/O Size 2 Kbytes for index leaf pages. | | | With LRU Buffer Replacement Strategy for index leaf pages. | | | Using I/O Size 2 Kbytes for data pages. | | | With LRU Buffer Replacement Strategy for data pages.
If there is a nonclustered index that includes the partitioning column, there is no reason for Adaptive Server to access the data pages and the query executes in serial:
create index RA2_NC2 on RA2(a3,a1,a2) select a3 from RA2 where a3 > 300
QUERY PLAN FOR STATEMENT 1 (at line 1). 1 operator(s) under root The type of query is SELECT. ROOT:EMIT Operator | SCAN Operator | FROM TABLE
| RA2 | Index : RA2_NC2 | Forward Scan. | Positioning by key. | Index contains all needed columns. Base table will not be read. | Keys are: | a3 ASC | Using I/O Size 2 Kbytes for index leaf pages. | With LRU Buffer Replacement Strategy for index leaf pages.
With a clustered index on an all-pages-locked table, a hash-based scan strategy is not permitted. The only allowable strategy is a partitioned scan. Adaptive Server uses a partitioned scan if that is necessary. For a data-only-locked table, a clustered index is usually a placement index, which behaves as a nonclustered index. All discussions pertaining to a nonclustered index on an all-pages-locked table apply to a clustered index on a data-only-locked table as well.
Adaptive Server supports clustered and nonclustered local indexes.
Local clustered indexes allow multiple threads to scan each data partition in parallel, which can greatly improve performance. To take advantage of this parallelism, use a partitioned clustered index. On a local index, data is sorted separately within each partition. The information in each data partition conforms to the boundaries established when the partitions were created, which makes it possible to enforce unique index keys across the entire table.
Unique, clustered local indexes have the following restrictions:
Index columns must include all partition columns.
Partition columns must have the same order as the index definition's partition key.
Unique, clustered local indexes cannot be included on a round-robin table with more than one partition.
Adaptive Server supports local, nonclustered indexes on partitioned tables.
There is, however, a slight difference when using local indexes. When doing a covered index scan of a local nonclustered index, Adaptive Server can still use a parallel scan because the index pages are partitioned as well.
To illustrate the difference, this example creates a local nonclustered index:
create index RA2_NC2L on RA2(a3,a1,a2) local index select a3 from RA2 where a3 > 300
QUERY PLAN FOR STATEMENT 1 (at line 1). Executed in parallel by coordinating process and 2 worker processes. 3 operator(s) under root The type of query is SELECT. ROOT:EMIT Operator |EXCHANGE Operator (Merged) |Executed in parallel by 2 Producer and 1 Consumer processes. | | |EXCHANGE:EMIT Operator | | | | |SCAN Operator | | | FROM TABLE | | | RA2 | | | Index : RA2_NC2L | | | Forward Scan. | | | Positioning by key. | | | Index contains all needed columns. Base table will not be read. | | | Keys are: | | | a3 ASC | | | Executed in parallel with a 2-way partition scan. | | | Using I/O Size 2 Kbytes for index leaf pages. | | | With LRU Buffer Replacement Strategy for index leaf pages.
Sometimes, Adaptive Server chooses a hash-based scan on a local index. This occurs when a different parallel degree is needed or when the data in the partition is skewed such that a hash-based parallel scan is preferred.
