![]()
![]()
![]()
![]()
Creates new tables and optional integrity constraints.
Defines computed columns.
Defines table, row, and partition compression levels.
Defines encrypted columns and decrypt defaults on encrypted columns.
Defines the table’s partition property. Syntax for creating table partitions is listed separately. See the syntax for partitions.
create table [[database.[owner].]table_name (column_name datatype
[default {constant_expression | user | null}]
[{identity | null | not null}]
[ in row [(length)] | off row ]
[[constraint constraint_name]
{{unique | primary key}
[clustered | nonclustered] [asc | desc]
[with {fillfactor = pct,
max_rows_per_page = num_rows,}
reservepagegap = num_pages]
dml_logging = {full | minimal}
[deferred_allocation | immediate_allocation])
[on segment_name]
| references [[database.]owner.]ref_table
[(ref_column)]
[match full]
| check (search_condition)}]}
[[encrypt [with [database.[owner].]key_name]
[decrypt_default constant_expression | null]]
[not compressed]
[compressed = {compression_level | not compressed}
[[constraint [[database.[owner].]key_name]
{unique | primary key}
[clustered | nonclustered]
(column_name [asc | desc]
[{, column_name [asc | desc]}...])
[with {fillfactor = pct
max_rows_per_page = num_rows,
reservepagegap = num_pages}]
[on segment_name]
| foreign key (column_name [{,column_name}...])
references [[database.]owner.]ref_table
[(ref_column [{, ref_column}...])]
[match full]
| check (search_condition) ...}
[{, {next_column | next_constraint}}...])
[lock {datarows | datapages | allpages}]
[with {max_rows_per_page = num_rows,
exp_row_size = num_bytes,
reservepagegap = num_pages,
identity_gap = value
transfer table [on | off]
dml_logging = {full | minimal}
compression = {none | page | row}}]
lob_compression = off | compression_level
[on segment_name]
[partition_clause]
[[external table] at pathname]
[for load]
compression_clause::=
with compression = {none | page | row}
Use this syntax for partitions:
partition_clause::= partition by range (column_name[, column_name]...)
([partition_name] values <= ({constant | MAX}
[, {constant | MAX}] ...)
[compression_clause] [on segment_name]
[, [partition_name] values <= ({constant | MAX}
[, {constant | MAX}] ...)
[compression_clause] [on segment_name]]...)
| partition by hash (column_name[, column_name]...)
{ (partition_name
[compression_clause] [on segment_name]
[, partition_name
[compression_clause] [on segment_name]]...)
| number_of_partitions
[on (segment_name[, segment_name] ...)]}
| partition by list (column_name)
([partition_name] values (constant[, constant] ...)
[compression_clause] [on segment_name]
[, [partition_name] values (constant[, constant] ...)
[compression_clause] [on segment_name]] ...)
| partition by roundrobin
{ (partition_name [on segment_name]
[, partition_name
[compression_clause] [on segment_name]]...)
| number_of_partitions
[on (segment_name[, segment_name]...)]}
Use this syntax for computed columns
create table [[database.[owner].] table_name
(column_name {compute | as}
computed_column_expression
[[materialized] [not compressed]] | [not materialized]}
Use this syntax to create a virtually hashed table
create table [database.[owner].]table_name
. . .
| {unique | primary key}
using clustered
(column_name [asc | desc] [{, column_name [asc | desc]}...])=
(hash_factor [{, hash_factor}...])
with max num_hash_values key
is the explicit name of the new table. Specify the database name if the table is in another database, and specify the owner’s name if more than one table of that name exists in the database. The default value for owner is the current user, and the default value for database is the current database.
You cannot use a variable for the table name. The table name must be unique within the database and to the owner. If you have set quoted_identifier on, you can use a delimited identifier for the table name. Otherwise, it must conform to the rules for identifiers. For more information about valid table names, see “Identifiers” on page 359 in Chapter 4, “Expressions, Identifiers, and Wildcard Characters,” of Reference Manual: Building Blocks.
You can create a temporary table by preceding the table name with either a pound sign (#) or “tempdb..”. See “Tables beginning with # (temporary tables)” on page 362 in Chapter 4, “Expressions, Identifiers, and Wildcard Characters,” of Reference Manual: Building Blocks.
You can create a table in a different database, as long as you are listed in the sysusers table and have create table permission for that database. For example, you can use either of the following to create a table called newtable in the database otherdb:
create table otherdb..newtable
create table otherdb.yourname.newtable
is the name of the column in the table. It must be unique in the table. If you have set quoted_identifier on, you can use a delimited identifier for the column. Otherwise, it must conform to the rules for identifiers. For more information about valid column names, see Chapter 4, “Expressions, Identifiers, and Wildcard Characters,” of Reference Manual: Building Blocks.
is the datatype of the column. System or user-defined datatypes are acceptable. Certain datatypes expect a length, n, in parentheses:
datatype (n)
Others expect a precision, p, and scale, s:
datatype (p,s)
See Chapter 1, “System and User-Defined Datatypes” in Reference Manual: Building Blocks for more information.
If Java is enabled in the database, datatype can be the name of a Java class, either a system class or a user-defined class, that has been installed in the database. See Java in Adaptive Server Enterprise for more information.
specifies a default value for a column. If you specify a default, and the user does not provide a value for the column when inserting data, Adaptive Server inserts the default value. The default can be a constant expression or a built-in, to insert the name of the user who is performing the insert, or null, to insert the null value. Adaptive Server generates a name for the default in the form of tabname_colname_objid, where tabname is the first 10 characters of the table name, colname is the first 5 characters of the column name, and objid is the object ID number for the default. Defaults declared for columns with the IDENTITY property have no effect on column values.
You can reference global variables in the default section of create table statements that do not reference database objects. You cannot, however, use global variables in the check section of create table.
is a constant expression to use as a default value for the column. It cannot include global variables, the name of any columns, or other database objects, but can include built-in functions that do not reference database objects. This default value must be compatible with the datatype of the column, or Adaptive Server generates a datatype conversion error when attempting to insert the default.
specifies that Adaptive Server should insert the user name or the null value as the default if the user does not supply a value. For user, the datatype of the column must be either char (30) or varchar (30). For null, the column must allow null values.
indicates that the column has the IDENTITY property. Each table in a database can have one IDENTITY column with a datatype of:
exact numeric and a scale of 0; or
Any of the integer datatypes, including signed or unsigned bigint, int, smallint, or tinyint.
IDENTITY columns are not updatable and do not allow nulls.
IDENTITY columns are used to store sequential numbers—such as invoice numbers or employee numbers—that are generated automatically by Adaptive Server. The value of the IDENTITY column uniquely identifies each row in a table.
specifies Adaptive Server behavior during data insertion if no default exists.
null specifies that Adaptive Server assigns a null value if a user does not provide a value.
not null specifies that a user must provide a non-null value if no default exists.
The properties of a bit-type column must always be not null.
If you do not specify null or not null, Adaptive Server uses not null by default. However, you can switch this default using sp_dboption to make the default compatible with the SQL standards.
instructs Adaptive Server to store data in the LOB column as in-row whenever there is enough space in the data page. The LOB column’s data is stored either fully as in-row or fully off-row.
(optional) specifies the maximum size at which LOB column data can be stored as in-row. Anything larger than this value is stored off-row, while anything equal to or less than length is stored as in-row, as long as there is enough space on the page.
When you do not specify length, Adaptive Server uses the database-wide setting for in-row length.
(optional) provides default behavior for storing LOB columns off-row. Adaptive Server assumes this behavior for your new table unless you specify in row. If you do not specify the off row clause and you set the database-wide in-row length, create table creates the LOB column as an in-row LOB column.
specifies whether a Java-SQL column is stored separate from the row (off row) or in storage allocated directly in the row (in row).
The default value is off row. See Java in Adaptive Server Enterprise.
specifies the maximum size of the in-row column. An object stored in-row can occupy up to approximately 16K bytes, depending on the page size of the database server and other variables. The default value is 255 bytes.
introduces the name of an integrity constraint.
constraint_name is the name of the constraint. It must conform to the rules for identifiers and be unique in the database. If you do not specify the name for a referential or check constraint, Adaptive Server generates a name in the form tabname_colname_objectid where:
tabname – is the first 10 characters of the table name
colname – is the first 5 characters of the column name
objectid – is the object ID number for the constraint
If you do not specify the name for a unique or primary key constraint, Adaptive Server generates a name in the format tabname_colname_tabindid, where tabindid is a string concatenation of the table ID and index ID.
constrains the values in the indicated column or columns so that no two rows have the same value. This constraint creates a unique index that can be dropped only if the constraint is dropped using alter table.
constrains the values in the indicated column or columns so that no two rows have the same value, and so that the value cannot be NULL. This constraint creates a unique index that can be dropped only if the constraint is dropped using alter table.
specifies that the index created by a unique or primary key constraint is a clustered or nonclustered index. clustered is the default for primary key constraints; nonclustered is the default for unique constraints. There can be only one clustered index per table. See create index for more information.
specifies whether the index created for a constraint is to be created in ascending or descending order for each column. The default is ascending order.
specifies how full Adaptive Server makes each page when it creates a new index on existing data. The fillfactor percentage is relevant only when the index is created. As the data changes, the pages are not maintained at any particular level of fullness.
The default for fillfactor is 0; this is used when you do not include with fillfactor in the create index statement (unless the value has been changed with sp_configure). When specifying a fillfactor, use a value between 1 and 100.
A fillfactor of 0 creates clustered indexes with completely full pages and nonclustered indexes with completely full leaf pages. It leaves a comfortable amount of space within the index B-tree in both the clustered and nonclustered indexes. There is seldom a reason to change the fillfactor.
If the fillfactor is set to 100, Adaptive Server creates both clustered and nonclustered indexes with each page 100 percent full. A fillfactor of 100 makes sense only for read-only tables—tables to which no data is ever added.
fillfactor values smaller than 100 (except 0, which is a special case) cause Adaptive Server to create new indexes with pages that are not completely full. A fillfactor of 10 might be a reasonable choice if you are creating an index on a table that will eventually hold a great deal more data, but small fillfactor values cause each index (or index and data) to take more storage space.
If CIS is enabled, you cannot use fillfactor for remote servers.
WARNING! Creating a clustered index with a fillfactor affects the amount of storage space your data occupies, since Adaptive Server redistributes the data as it creates the clustered index.
decrypt_default allows the sso to specify a value to be returned to users who do not have decrypt permissions on the encrypted column. Decrypt default values will be substituted for text, image, or unitext columns retrieved through the select statement.
limits the number of rows on data pages and the leaf-level pages of indexes. Unlike fillfactor, the max_rows_per_page value is maintained when data is inserted or deleted.
If you do not specify a value for max_rows_per_page, Adaptive Server uses a value of 0 when creating the table. Values for tables and clustered indexes are between 0 and 256. The maximum number of rows per page for nonclustered indexes depends on the size of the index key; Adaptive Server returns an error message if the specified value is too high.
A max_rows_per_page of 0 creates clustered indexes with full data pages and nonclustered indexes with full leaf pages. It leaves a comfortable amount of space within the index B-tree in both clustered and nonclustered indexes.
Using low values for max_rows_per_page reduces lock contention on frequently accessed data. However, using low values also causes Adaptive Server to create new indexes with pages that are not completely full, uses more storage space, and may cause more page splits.
If CIS is enabled, and you create a proxy table, then max_rows_per_page is ignored. Proxy tables do not contain any data. If max_rows_per_page is used to create a table, and later a proxy table is created to reference that table, then the max_rows_per_page limits apply when you insert or delete through the proxy table.
specifies the ratio of filled pages to empty pages that are to be left during extent I/O allocation operations. For each specified num_pages, an empty page is left for future expansion of the table. Valid values are 0 – 255. The default value is 0.
determines the amount of logging for insert, update and delete operations, and for some forms of bulk inserts. One of
full – Adaptive Server logs all transactions
minimal – Adaptive Sever does not log row or page changes
defers a table or index’s creation until the table is needed. Deferred tables are created at the first insert.
Explicitly creates a table when you have enabled sp_dboption 'deferred table allocation'.
when used with the constraint option, specifies that the index is to be created on the named segment. Before the on segment_name option can be used, the device must be initialized with disk init, and the segment must be added to the database with sp_addsegment. See your system administrator or use sp_helpsegment for a list of the segment names available in your database.
If you specify clustered and use the on segment_name option, the entire table migrates to the segment you specify, since the leaf level of the index contains the actual data pages.
specifies a column list for a referential integrity constraint. You can specify only one column value for a column constraint. By including this constraint with a table that references another table, any data inserted into the referencing table must already exist in the referenced table.
To use this constraint, you must have references permission on the referenced table. The specified columns in the referenced table must be constrained by a unique index (created by either a unique constraint or a create index statement). If no columns are specified, there must be a primary key constraint on the appropriate columns in the referenced table. Also, the datatypes of the referencing table columns must match the datatype of the referenced table columns.
is the name of the table that contains the referenced columns. You can reference tables in another database. Constraints can reference as many as 192 user tables and internally generated worktables.
is the name of the column or columns in the referenced table.
specifies that if all values in the referencing columns of a referencing row are:
Null – the referential integrity condition is true.
Non-null values – if there is a referenced row where each corresponding column is equal in the referenced table, then the referential integrity condition is true.
If they are neither, then the referential integrity condition is false when:
All values are non-null and not equal, or
Some of the values in the referencing columns of a referencing row are non-null values, while others are null.
specifies the check constraint on the column values and a search_condition constraint that Adaptive Server enforces for all the rows in the table. You can specify check constraints as table or column constraints; create table allows multiple check constraints in a column definition.
Although you can reference global variables in the default section of create table statements, you cannot use them in the check section.
The constraints can include:
A list of constant expressions introduced with in
A set of conditions introduced with like, which may contain wildcard characters
Column and table check constraints can reference any columns in the table.
An expression can include arithmetic operators and functions. The search_condition cannot contain subqueries, aggregate functions, host variables, or parameters.
creates an encrypted column. Specify the database name if the key is in another database. Specify the owner’s name if key_name is not unique to the database. The default value for owner is the current user, and the default value for database is the current database.
The table creator must have select permission on the key. If you do nto supply key_name, Adaptive Server looks for a default key in the database.
keyname identifies a key created using create encryption key. The creator of the table must have select permission on keyname. If keyname is not supplied, Adaptive Server looks for a default key created using the as default clause on create encryption key or alter encryption key.
See “Encrypting Data,” in the Encrypted Columns Users Guide for a list of supported datatypes.
specifies that this column returns a default value for users who do not have decrypt permissions, and constant_expression is the constant value Adaptive Server returns on select statements instead of the decrypted value. The value can be NULL on nullable columns only. If the decrypt default value cannot be converted to the column’s datatype, Adaptive Server catches the conversion error only when it executes the query.
indicates if the data in the row is compressed and to what level.
specifies that the listed columns are foreign keys in this table whose target keys are the columns listed in the following references clause. The foreign-key syntax is permitted only for table-level constraints, not for column-level constraints.
indicates that you can include additional column definitions or table constraints (separated by commas) using the same syntax described for a column definition or table constraint definition.
specifies the locking scheme to be used for the table. The default is the server-wide setting for the configuration parameter lock scheme.
specifies the expected row size; applies only to datarows and datapages locking schemes, and only to tables with variable-length rows. Valid values are 0, 1, and any value between the minimum and maximum row length for the table. The default value is 0, which means a server-wide setting is applied.
specifies the identity gap for the table. This value overrides the system identity gap setting for this table only.
value is the identity gap amount. For more information about setting the identity gap, see “IDENTITY columns”.
marks the table for incremental transfer. The default value of this parameter is off.
determines the amount of logging for insert, update and delete operations, and for some forms of bulk inserts. One of
full – Adaptive Server logs all transactions
minimal – Adaptive Sever does not log row or page changes
indicates the level of compression at the table or the partition level. Specifying the compression level for the partition overrides the compression level for the table. Adaptive Server compresses individual columns only in partitions that are configured for compression.
none – the data in this table or partition is not compressed. For partitions, none indicates that data in this partition remains uncompressed even if the table compression is altered to row or page compression.
row – compresses one or more data items in an individual row. Adaptive Server stores data in a row compressed form only if the compressed form saves space compared to an uncompressed form. Set row compression at the partition or table level.
page – when the page fills, existing data rows that are row-compressed are then compressed using page-level compression to create page-level dictionary, index, and character-encoding entries. Set page compression at the partition or table level.
Adaptive Server compresses data at the page level only after it has compressed data at the row level, so setting the compression-level to page implies both page and row compression.
Determines the compression level for the table. The table has no LOB compression if you select off.
Table compression level. The compression levels are:
0 – the row is not compressed.
1 through 9 – Adaptive Server uses ZLib compression. Generally, the higher the compression number, the more Adaptive Server compresses the LOB data, and the greater the ratio between compressed and uncompressed data (that is the greater the amount of space savings, in bytes, for the compressed data versus the size of the uncompressed data).
However, the amount of compression depends on the LOB content, and the higher the compression level , the more CPU-intensive the process. That is, level 9 provides the highest compression ratio but also the heaviest CPU usage.
100 – Adaptive Server uses FastLZ compression. The compression ratio that uses the least CPU usage; generally used for shorter data.
101 – Adaptive Server uses FastLZ compression. A value of 101 uses slightly more CPU than a value of 100, but uses a better compression ratio than a value of 100.
The compression algorithm ignores rows that do not use LOB data.
specifies the name of the segment on which to place the table. When using on segment_name, the logical device must already have been assigned to the database with create database or alter database, and the segment must have been created in the database with sp_addsegment. See your system administrator or use sp_helpsegment for a list of the segment names available in your database.
When used for partitions, specifies the segment on which to place the partition.
specifies that the object is a remote table or view. external table is the default, so specifying this is optional.
creates a table available only to bcp in and alter table unpartition operations. You can use row_count() on a table you create using for load.
specifies records are to be partitioned according to specified ranges of values in the partitioning column or columns.
when used in the partition_clause, specifies a partition key column.
specifies the name of a new partition on which table records are stored. Partition names must be unique within the set of partitions on a table or index. Partition names can be delimited identifiers if set quoted_identifier is on. Otherwise, they must be valid identifiers.
If partition_name is omitted, Adaptive Server creates a name in the form table_name_patition_id. Adaptive Server truncates partition names that exceed the allowed maximum length.
when used in the partition_clause, specifies the segment on which the partition is to be placed. Before the on segment_name option can be used, the device must be initialized with disk init, and the segment must be added to the database using the sp_addsegment system procedure. See your system administrator or use sp_helpsegment for a list of the segment names available in your database.
specifies the inclusive upper bound of values for a named partition. Specifying a constant value for the highest partition bound imposes an implicit integrity constraint on the table. The keyword MAX specifies the maximum value in a given datatype.
specifies records are to be partitioned by a system-supplied hash function. The function computes the hash value of the partition keys that specify the partition to which records are assigned.
specifies records are to be partitioned according to literal values specified in the named column. Only one column can partition a list-partitioned table. You can specify up to 250 distinct list values for each partition.
specifies records are to be partitioned in a sequential manner. A round-robin-partitioned table has no partitioning key. Neither the user nor the optimizer knows the partition of a particular record.
specifies the location of the remote object. Using the at pathname clause results in the creation of a proxy table.
pathname takes the form server_name.dbname.owner.object;aux1.aux2, where:
server_name (required) – is the name of the server that contains the remote object.
dbname (optional) – is the name of the database managed by the remote server that contains this object.
owner (optional) – is the name of the remote server user that owns the remote object.
object (required) – is the name of the remote table or view.
aux1.aux2 (optional) – is a string of characters that is passed to the remote server during a create table or create index command. This string is used only if the server is class db2. aux1 is the DB2 database in which to place the table, and aux2 is the DB2 tablespace in which to place the table.
reserved keywords that you can use interchangeably to indicate that a column is a computed column.
is any valid T-SQL expression that does not contain columns from other tables, local variables, aggregate functions, or subqueries. It can be one or a combination of column name, constant, function, global variable, or case expression, connected by one or more operators. You cannot cross-reference between computed columns except when virtual computed columns reference materialize computed columns.
specifies whether or not the computed column is materialized and physically stored in the table. If neither keyword is specified, a computed column by default is not materialized, and thus not physically stored in the table.
indicates you are creating a virtually hashed table. The list of columns are treated as key columns for this table.
because rows are placed based on their hash function, you cannot use [asc | desc] for the hash region. If you provide an order for the key columns of virtually hashed tables, it is used only in the overflow clustered region.
required for the hash function for virtually hashed tables. For the hash function, a hash factor is required for every key column. These factors are used with key values to generate hash value for a particular row.
the maximum number of hash values that you can use. Defines the upper bound on the output of this hash function.
Creates the foo table using the @@spid global variable with the default parameter:
create table foo ( a int , b int default @@spid )
Creates the titles table:
create table titles ( title_id tid not null , title varchar (80) not null , type char (12) not null , pub_id char (4) null , price money null , advance money null , total_sales int null , notes varchar (200) null , pubdate datetime not null , contract bit not null )
Creates a table mytable using for load:
create table mytable ( col1 int , col2 int , col3 (char 50) ) partitioned by roundrobin 3 for load
The new table is unavailable to any user activities until it is unpartitioned.
Load the data into mytable, using bcp in.
Unpartition mytable.
The table is now available for any user activities.
Creates the compute table. The table name and the column names, max and min, are enclosed in double quotes because they are reserved words. The total score column name is enclosed in double quotes because it contains an embedded blank. Before creating this table, you must set quoted_identifier on.
create table "compute" ( "max" int , "min" int , "total score" int )
Creates the sales table and a clustered index in one step with a unique constraint. (In the pubs2 database installation script, there are separate create table and create index statements):
create table sales ( stor_id char (4) not null , ord_num varchar (20) not null , date datetime not null , unique clustered (stor_id, ord_num) )
Creates the salesdetail table with two referential integrity constraints and one default value. There is a table-level, referential integrity constraint named salesdet_constr and a column-level, referential integrity constraint on the title_id column without a specified name. Both constraints specify columns that have unique indexes in the referenced tables (titles and sales). The default clause with the qty column specifies 0 as its default value.
create table salesdetail ( stor_id char (4) not null , ord_num varchar (20) not null , title_id tid not null references titles (title_id) , qty smallint default 0 not null , discount float not null, constraint salesdet_constr foreign key (stor_id, ord_num) references sales (stor_id, ord_num) )
Creates the table publishers with a check constraint on the pub_id column. This column-level constraint can be used in place of the pub_idrule included in the pubs2 database.
create rule pub_idrule
as @pub_id in ("1389", "0736", "0877", "1622", "1756")
or @pub_id like "99[0-9][0-9]"
create table publishers (
pub_id char (4) not null
check (pub_id in ("1389", "0736", "0877", "1622",
"1756")
or pub_id like "99[0-9][0-9]")
, pub_name varchar (40) null
, city varchar (20) null
, state char (2) null
)
Specifies the ord_num column as the IDENTITY column for the sales_daily table. The first time you insert a row into the table, Adaptive Server assigns a value of 1 to the IDENTITY column. On each subsequent insert, the value of the column increments by 1.
create table sales_daily ( stor_id char (4) not null , ord_num numeric (10,0) identity , ord_amt money null )
Specifies the datapages locking scheme for the new_titles table and an expected row size of 200:
create table new_titles ( title_id tid , title varchar (80) not null , type char (12) , pub_id char (4) null , price money null , advance money null , total_sales int null , notes varchar (200) null , pubdate datetime , contract bit ) lock datapages with exp_row_size = 200
Specifies the datarows locking scheme and sets a reservepagegap value of 16 so that extent I/O operations leave 1 blank page for each 15 filled pages:
create table new_publishers ( pub_id char (4) not null , pub_name varchar (40) null , city varchar (20) null , state char (2) null ) lock datarows with reservepagegap = 16
Creates a table named big_sales with minimal logging:
create table big_sales ( storid char(4) not null , ord_num varchar(20) not null , order_date datetime not null ) with dml_logging = minimal
Creates a deferred table named im_not_here_yet:
create table im_not_here_yet ( col_1 int, col_2 varchar(20) ) with deferred_allocation
Creates a table named mytable, that uses the locking scheme datarows, and permits incremental transfer:
create table mytable ( f1 int , f2 bigint not null , f3 varchar (255) null ) lock datarows with transfer table on
Creates a table named genre with row-level compression:
create table genre ( mystery varchar(50) not null , novel varchar(50) not null , psych varchar(50) not null , history varchar(50) not null , art varchar(50) not null , science varchar(50) not null , children varchar(50) not null , cooking varchar(50) not null , gardening varchar(50) not null , poetry varchar(50) not null ) with compression = row
Creates a table named sales on segments seg1, seg2, and seg3, with compression on seg1:
create table sales (
store_id int not null
, order_num int not null
, date datetime not null
)
partition by range (date)
( Y2008 values <= ('12/31/2008')
with compression = page on seg1,
Y2009 values <= ('12/31/2009') on seg2,
Y2010 values <= ('12/31/2010') on seg3)
Creates the email table, which uses a LOB compression level of 5:
create table email ( user_name char (10) , mailtxt text , photo image , reply_mails text) with lob_compression = 5
Creates a constraint supported by a unique clustered index; the index order is ascending for stor_id and descending for ord_num:
create table sales_south ( stor_id char (4) not null , ord_num varchar (20) not null , date datetime not null , unique clustered (stor_id asc, ord_num desc) )
Creates a table named t1 at the remote server SERVER_A and creates a proxy table named t1 that is mapped to the remote table:
create table t1 ( a int , b char (10) ) at "SERVER_A.db1.joe.t1"
Creates a table named employees. name is of type varchar, home_addr is a Java-SQL column of type Address, and mailing_addr is a Java-SQL column of type Address2Line. Both Address and Address2Line are Java classes installed in the database:
create table employees ( name varchar (30) , home_addr Address , mailing_addr Address2Line )
Creates a table named mytable with an identity column. The identity gap is set to 10, which means ID numbers are allocated in memory in blocks of ten. If the server fails or is shut down with no wait, the maximum gap between the last ID number assigned to a row and the next ID number assigned to a row is 10 numbers:
create table mytable ( IdNum numeric (12,0) identity ) with identity_gap = 10
Creates a table my_publishers, which is partitioned by list according to values in the state column. See the Transact-SQL Users Guide for more information about creating table partitions.
create table my_publishers (
pub_id char (4) not null
, pub_name varchar (40) null
, city varchar (20) null
, state char (2) null
)
partition by list (state) (
west values ('CA', 'OR', 'WA') on seg1
, east values ('NY', 'MA') on seg2
)
Creates the table fictionsales, which is partitioned by range according to values in the date column:
create table fictionsales (
store_id int not null
, order_num int not null
, date datetime not null
)
partition by range (date) (
q1 values <= ("3/31/2005") on seg1
, q2 values <= ("6/30/2005") on seg2
, q3 values <= ("9/30/2005") on seg3
, q4 values <= ("12/31/2005") on seg4
)
Creates the table currentpublishers, which is partitioned by round-robin:
create table currentpublishers ( pub_id char (4) not null , pub_name varchar (40) null , city varchar (20) null , state char (2) null ) partition by roundrobin 3 on (seg1)
Creates the table mysalesdetail, which is partitioned by hash according to values in the ord_num column:
create table mysalesdetail ( store_id char (4) not null , ord_num varchar (20) not null , title_id tid not null , qty smallint not null , discount float not null ) partition by hash (ord_num) ( p1 on seg1 , p2 on seg2 , p3 on seg3 )
Creates a table called mytitles with one materialized computed column:
create table mytitles ( title_id tid not null , title varchar (80) not null , type char (12) not null , pub_id char (4) null , price money null , advance money null , total_sales int null , notes varchar (200) null , pubdate datetime not null , sum_sales compute price * total_sales materialized )
Creates an employee table with a nullable encrypted column. Adaptive Server uses the database default encryption key to encrypt the ssn data:
create table employee_table ( ssn char(15) null encrypt name char(50) , deptid int )
Creates a customer table with an encrypted column for credit card data:
create table customer ( ccard char(16) unique encrypt with cc_key decrypt_default 'XXXXXXXXXXXXXXXX', name char(30) )
The ccard column has a unique constraint and uses cc_key for encryption. Because of the decrypt_default specifier, Adaptive Server returns the value ‘XXXXXXXXXXXXXXXX’ instead of the actual data when a user without decrypt permission selects the ccard column.
Creates a table that specifies description as an in-row LOB column 300 bytes long, notes as an in-row LOB column without a specified length (inheriting the size of the off-row storage), and the reviews column as stored off-row regardless of condition:
create table new_titles ( title_id tid not null , title varchar (80) not null , type char (12) null , price money null , pubdate datetime not null , description text in row (300) , notes text in row , reviews text off row )
Creates a virtually hashed table named orders on the pubs2 database on the order_seg segment:
create table orders ( id int , age int , primary key using clustered (id,age) = (10,1) with max 1000 key ) on order_seg
The layout for the data is:
The order_seg segment starts on page ID 51200.
The ID for the first data object allocation map (OAM) page is 51201.
The maximum rows per page is 168.
The row size is 10.
The root index page of the overflow clustered region is 51217.
Figure 1-1: The data layout for the example
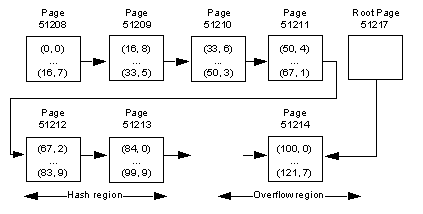
Creates a virtually hashed table named orders on the pubs2 database on the order_seg segment:
create table orders ( id int default NULL , age int , primary key using clustered (id,age) = (10,1) with max 100 key , name varchar(30) ) on order_seg
The layout for the data is:
The order_seg segment starts on page ID 51200.
The ID for the first data OAM page is 51201.
The maximum rows per page is 42.
The row size is 45.
The root index page of the overflow clustered region is 51217.
Figure 1-2: The data layout for the example
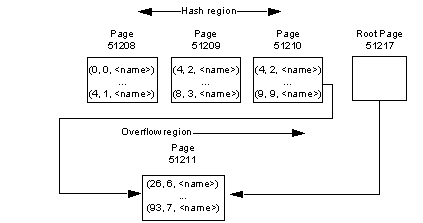
create table creates a table and optional integrity constraints. The table is created in the currently open database unless you specify a different database in the create table statement. You can create a table or index in another database, if you are listed in the sysusers table and have create table permission in the database.
Space is allocated to tables and indexes in increments of one extent, or eight pages, at a time. Each time an extent is filled, another extent is allocated. To see the amount of space allocated and used by a table, use sp_spaceused.
The maximum length for in-row Java columns is determined by the maximum size of a variable-length column for the table’s schema, locking style, and page size.
create table performs error checking for check constraints before it creates the table.
When using create table from CIS with a column defined as char (n) NULL, CIS creates the column as varchar (n) on the remote server.
Use the asc and desc keywords after index column names to specify the sort order for the index. Creating indexes so that columns are in the same order specified in the order by clause of queries eliminates the sorting step during query processing.
If an application inserts short rows into a data-only-locked table and updates them later so that their length increases, use exp_row_size to reduce the number of times that rows in data-only-locked tables are forwarded to new locations.
The location information provided by the at keyword is the same information that is provided by sp_addobjectdef. The information is stored in the sysattributes table.
The maximum number of columns in a table depends on the width of the columns and the server’s logical page size:
The sum of the columns’ sizes cannot exceed the server’s logical page size.
The maximum number of columns per table cannot exceed 1024.
The maximum number of variable-length columns for an all-pages lock table is 254.
For example, if your server uses a 2K logical page size and includes a table of integer columns, the maximum number of columns in the table is far fewer than 1024. (1024 * 4 bytes exceeds a 2K logical page size.)
You can mix variable- and fixed-length columns in a single table as long as the maximum number of columns does not exceed 1024. For example, if your server uses a 8K logical page size, a table configured for APL can have 254 nullable integer columns (these are variable-length columns) and 770 non-nullable integers, for a total of 1024 columns.
There can be as many as 2,000,000,000 tables per database and 1024 user-defined columns per table. The number of rows per table is limited only by available storage.
Although Adaptive Server does create tables in the following circumstances, you will receive errors about size limitations when you perform DML operations:
If the total row size for rows with variable-length columns exceeds the maximum column size
If the length of a single variable-length column exceeds the maximum column size
For data-only-locked tables, if the offset of any variable-length column other than the initial column exceeds the limit of 8191 bytes
Adaptive Server reports an error if the total size of all fixed-length columns, plus the row overhead, is greater than the table’s locking scheme and page size allows. These limits are described in Table 1-10.
Locking scheme |
Page size |
Maximum row length |
Maximum column length |
|---|---|---|---|
APL tables |
2K (2048 bytes) |
1962 bytes |
1960 bytes |
4K (4096 bytes) |
4010 bytes |
4008 bytes |
|
8K (8192 bytes) |
8106 bytes |
8104 bytes |
|
16K (16384 bytes) |
16298 bytes |
16296 bytes |
|
DOL tables |
2K (2048 bytes) |
1964 bytes |
1958 bytes |
4K (4096 bytes) |
4012 bytes |
4006 bytes |
|
8K (8192 bytes) |
8108 bytes |
8102 bytes |
|
16K (16384 bytes) |
16300 bytes |
16294 bytes If table does not include any variable-length columns |
|
16K (16384 bytes) |
16300 (subject to a max start offset of varlen = 8191) |
8191-6-2 = 8183 bytes If table includes at least one variable-length column.* |
|
* This size includes six bytes for the row overhead and two bytes for the row length field |
|||
The maximum number of bytes of variable length data per row depends on the locking scheme for the table:
Page size |
Maximum row length |
Maximum column length |
|---|---|---|
2K (2048 bytes) |
1962 |
1960 |
4K (4096 bytes) |
4010 |
4008 |
8K (8192 bytes) |
8096 |
8104 |
16K (16384 bytes) |
16298 |
16296 |
The maximum size of columns for a DOL table:
Page size |
Maximum row length |
Maximum column length |
|---|---|---|
2K (2048 bytes) |
1964 |
1958 |
4K (4096 bytes) |
4012 |
4006 |
8K (8192 bytes) |
8108 |
8102 |
16K (16384 bytes) |
16300 |
16294 |
If you create a DOL table with a variable-length column that exceeds a 8191-byte offset, you cannot add any rows to the column.
If you create tables with varchar, nvarchar, univarchar, or varbinary columns for which total defined width is greater than the maximum allowed row size, a warning message appears, but the table is created. If you try to insert more than the maximum number bytes into such a row, or to update a row so that its total row size is greater than the maximum length, Adaptive Server produces an error message, and the command fails.
When a create table command occurs within an if...else block or a while loop, Adaptive Server creates the schema for the table before determining whether the condition is true. This may lead to errors if the table already exists. To avoid this situation, either make sure a view with the same name does not already exist in the database or use an execute statement, as follows:
if not exists (select * from sysobjects where name="my table") begin execute "create table mytable (x int)" end
You cannot issue create table with a declarative default or check constraint and then insert data into the table in the same batch or procedure. Either separate the create and insert statements into two different batches or procedures, or use execute to perform the actions separately.
You cannot use the following variable in create table statements that include defaults:
declare @p int select @p = 2 create table t1 (c1 int default @p, c2 int)
Doing so results in error message 154: “Variable is not allowed in default.”
Virtually-hashed tables have these restrictions:
SQL user-defined functions are not currently supported with create proxy table, create table at remote server, or alter table.
![]() The execution of SQL functions requires the syntax username.functionname().
The execution of SQL functions requires the syntax username.functionname().
Virtually-hashed tables must have unique rows. Virtually hashed tables do not allow multiple rows with the same key-column values because Adaptive Server cannot keep one row in the hash region and another with the same key-column value in the overflow clustered region.
You must create each virtually-hashed table on an exclusive segment.
Unless you state otherwise, Adaptive Server:
Sets data compression to NULL when you create a table.
Preserves the existing compression level when you modify a table.
Sets all partitions to the compression level specified in the create table clause.
You can create a table with table-level compression but leave some partitions uncompressed, which allows you to maintain uncompressed data in an active partitions format, and to periodically compress the data when appropriate.
Adaptive Server supports partition-level compression for all forms of partitioning except round-robin partitions.
Columns marked as not compressed are not selected for row or page compression. However, in-row columns (including materialized computed columns) are eligible for compression:
All fixed-length data smaller than 4 bytes is ineligible for row compression. However, Adaptive Server may compress these datatypes during page-index compression.
All data, fixed or with a variable length of 4 bytes or larger, is eligible for row compression.
By default, Adaptive Server creates uncompressed nonmaterialized computed columns.
Adaptive Server first compresses the columns eligible for compression at the row level. If the compressed row is longer than the uncompressed row, Adaptive Server discards the compressed row and stores the uncompressed row on disk, ensuring that compression does not waste space.
Data pages may simultaneously contain compressed and uncompressed data rows.
You may compress fixed-length columns.
You can use the with exp_row_size clause to create compressed data-only-locked (DOL) tables only for fixed-length rows. You cannot use the with exp_row_size clause on allpages-locked (APL) tables.
If you specify an expected row size, but the uncompressed row length is smaller than the expected row size, Adaptive Server does not compress the row.
After you enable compression for a table, all bcp and DML operations that are executed on the table compress the data.
Compression may allow you to store more rows on a page, but it does not change the maximum row size of a table. However, it can change the effective minimum row size of a table.
Use not compressed for columns that could be row- or page-index compressed, but for which the nature of the column makes compression inapplicable or meaningless (for example, columns that use the bit datatype, encryption, or a timestamp column).
Compressing a table does not compress its indexes.
You cannot compress:
System tables
Worktables
In-row Java columns
Nonmaterialzed computed columns
IDENTITY columns
Timestamps added for data transfer
All datatypes; see the Compression Users Guide for a list of unsupported datatypes
Encrypted columns
You cannot create a table for compression if the minimum row size exceeds the size of the maximum user data row for the configured locking scheme and page size combination. For example, you cannot create a data-only-locked table with a 2K page size that includes column c1 with a char(2007) datatype because it exceeds the maximum user data row size. For row and page compression, Adaptive Server performs the same row size check as for a new table.
You cannot create a table for row or page compression that has only short, fixed-length columns smaller than 4 bytes.
Compressing data on LOB tables include these restrictions. You cannot:
Compress computed text columns
Issue LOB compression clauses (for example, lob_compression =) on regular columns, XML data
Use LOB compression for system and worktables
When you create a column from a user-defined datatype:
You cannot change the length, precision, or scale.
You can use a NULL type to create a NOT NULL column, but not to create an IDENTITY column.
You can use a NOT NULL type to create a NULL column or an IDENTITY column.
You can use an IDENTITY type to create a NOT NULL column, but the column inherits the IDENTITY property. You cannot use an IDENTITY type to create a NULL column.
Only columns with variable-length datatypes can store null values. When you create a NULL column with a fixed-length datatype, Adaptive Server automatically converts it to the corresponding variable-length datatype. Adaptive Server does not inform the user of the type change.
Table 1-11 lists the fixed-length datatypes and the variable-length datatypes to which they are converted. Certain variable-length datatypes, such as moneyn, are reserved types that cannot be used to create columns, variables, or parameters:
Original fixed-length datatype |
Converted to |
|---|---|
char |
varchar |
nchar |
nvarchar |
binary |
varbinary |
datetime |
datetimn |
float |
floatn |
bigint, int, smallint, tinyint |
intn |
unsigned bigint, unsigned int, unsigned smallint |
uintn |
decimal |
decimaln |
numeric |
numericn |
money and smallmoney |
moneyn |
You can create column defaults in two ways: by declaring the default as a column constraint in the create table or alter table statement, or by creating the default using the create default statement and binding it to a column using sp_bindefault.
For a report on a table and its columns, execute the system procedure sp_help.
Temporary tables are stored in the temporary database, tempdb.
The first 13 characters of a temporary table name must be unique per session. Such tables can be accessed only by the current Adaptive Server session. They are stored in tempdb..objects by their names plus a system-supplied numeric suffix, and they disappear at the end of the current session or when they are explicitly dropped.
Temporary tables created with the “tempdb..” prefix are shareable among Adaptive Server user sessions. Create temporary tables with the “tempdb..” prefix from inside a stored procedure only if you intend to share the table among users and sessions. To avoid inadvertent sharing of temporary tables, use the “#” prefix when creating and dropping temporary tables in stored procedures.
Temporary tables can be used by multiple users during an Adaptive Server session. However, the specific user session usually cannot be identified because temporary tables are created with the “guest” user ID of 2. If more than one user runs the process that creates the temporary table, each user is a “guest” user, so the uid values are all identical. Therefore, there is no way to know which user session in the temporary table is for a specific user. The system administrator can add the user to the temporary table using create login, in which case the individual uid is available for that user’s session in the temporary table.
You can associate rules, defaults, and indexes with temporary tables, but you cannot create views on temporary tables or associate triggers with them.
When you create a temporary table, you can use a user-defined datatype only if the type is in tempdb..systypes. To add a user-defined datatype to tempdb for only the current session, execute sp_addtype while using tempdb. To add the datatype permanently, execute sp_addtype while using model, then restart Adaptive Server so that model is copied to tempdb.
A table “follows” its clustered index. If you create a table on one segment, then create its clustered index on another segment, the table migrates to the segment where the index is created.
You can make inserts, updates, and selects faster by creating a table on one segment and its nonclustered indexes on another segment, if the segments are on separate physical devices. See “Using clustered or nonclustered indexes,” in Transact-SQL Users Guide.
Use sp_rename to rename a table or column.
After renaming a table or any of its columns, use sp_depends to determine which procedures, triggers, and views depend on the table, and redefine these objects.
WARNING! If you do not redefine these dependent objects, they no longer work after Adaptive Server recompiles them.
The create table statement helps control a database’s integrity through a series of integrity constraints as defined by the SQL standards. These integrity constraint clauses restrict the data that users can insert into a table. You can also use defaults, rules, indexes, and triggers to enforce database integrity.
Integrity constraints offer the advantages of defining integrity controls in one step during the table creation process and of simplifying the creation of those integrity controls. However, integrity constraints are more limited in scope and less comprehensive than defaults, rules, indexes, and triggers.
You must declare constraints that operate on more than one column as table-level constraints; declare constraints that operate on only one column as column-level constraints. Although the difference is rarely noticed by users, column-level constraints are checked only if a value in the column is being modified, while the table-level constraints are checked if there is any modification to a row, regardless of whether or not it changes the column in question.
Place column-level constraints after the column name and datatype, before the delimiting comma (see Example 5). Enter table-level constraints as separate comma-delimited clauses (see Example 4). Adaptive Server treats table-level and column-level constraints the same way; neither way is more efficient than the other.
You can create the following types of constraints at the table level or the column level:
A unique constraint does not allow two rows in a table to have the same values in the specified columns. In addition, a primary key constraint disallows null values in the column.
A referential integrity (references) constraint requires that the data being inserted or updated in specific columns has matching data in the specified table and columns.
A check constraint limits the values of the data inserted into the columns.
You can also enforce data integrity by restricting the use of null values in a column (using the null or not null keywords) and by providing default values for columns (using the default clause).
You can use sp_primarykey, sp_foreignkey, and sp_commonkey to save information in system tables, which can help clarify the relationships between tables in a database. These system procedures do not enforce key relationships or duplicate the functions of the primary key and foreign key keywords in a create table statement. For a report on keys that have been defined, use sp_helpkey. For a report on frequently used joins, execute sp_helpjoins.
Transact-SQL provides several mechanisms for integrity enforcement. In addition to the constraints you can declare as part of create table, you can create rules, defaults, indexes, and triggers. Table 1-12 summarizes the integrity constraints and describes the other methods of integrity enforcement:
In create table |
Other methods |
|---|---|
unique constraint |
create unique index (on a column that allows null values) |
primary key constraint |
create unique index (on a column that does not allow null values) |
references constraint |
|
check constraint (table level) |
|
check constraint (column level) |
create trigger or create rule and sp_bindrule |
default clause |
create default and sp_bindefault |
The method you choose depends on your requirements. For example, triggers provide more complex handling of referential integrity (such as referencing other columns or objects) than those declared in create table. Also, the constraints defined in a create table statement are specific for that table; unlike rules and defaults, you cannot bind them to other tables, and you can only drop or change them using alter table. Constraints cannot contain subqueries or aggregate functions, even on the same table.
create table can include many constraints, with these limitations:
The number of unique constraints is limited by the number of indexes that a table can have.
A table can have only one primary key constraint.
You can include only one default clause per column in a table, but you can define different constraints on the same column.
For example:
create table discount_titles (title_id varchar (6) default "PS7777" not null unique clustered references titles (title_id) check (title_id like "PS%"), new_price money)
Column title_id of the new table discount_titles is defined with each integrity constraint.
You can create error messages and bind them to referential integrity and check constraints. Create messages with sp_addmessage and bind them to the constraints with sp_bindmsg. See sp_addmessage and sp_bindmsg.
Adaptive Server evaluates check constraints before enforcing the referential constraints, and evaluates triggers after enforcing all the integrity constraints. If any constraint fails, Adaptive Server cancels the data modification statement; any associated triggers do not execute. However, a constraint violation does not roll back the current transaction.
In a referenced table, you cannot update column values or delete rows that match values in a referencing table. Update or delete from the referencing table first, then try updating or deleting from the referenced table.
You must drop the referencing table before you drop the referenced table; otherwise, a constraint violation occurs.
For information about constraints defined for a table, use sp_helpconstraint.
You can declare unique constraints at the column level or the table level. unique constraints require that all values in the specified columns be unique. No two rows in the table can have the same value in the specified column.
A primary key constraint is a more restrictive form of unique constraint. Columns with primary key constraints cannot contain null values.
![]() The create table statement’s unique and primary
key constraints create indexes that define unique or primary
key attributes of columns. sp_primarykey, sp_foreignkey,
and sp_commonkey define logical relationships
between columns. These relationships must be enforced using indexes
and triggers.
The create table statement’s unique and primary
key constraints create indexes that define unique or primary
key attributes of columns. sp_primarykey, sp_foreignkey,
and sp_commonkey define logical relationships
between columns. These relationships must be enforced using indexes
and triggers.
Table-level unique or primary key constraints appear in the create table statement as separate items and must include the names of one or more columns from the table being created.
unique or primary key constraints create a unique index on the specified columns. The unique constraint in Example 3 creates a unique, clustered index, as does:
create unique clustered index salesind on sales (stor_id, ord_num)
The only difference is the index name, which you could set to salesind by naming the constraint.
The definition of unique constraints in the SQL standard specifies that the column definition cannot allow null values. By default, Adaptive Server defines the column as not allowing null values (if you have not changed this using sp_dboption) when you omit null or not null in the column definition. In Transact-SQL, you can define the column to allow null values along with the unique constraint, since the unique index used to enforce the constraint allows you to insert a null value.
unique constraints create unique, nonclustered indexes by default; primary key constraints create unique, clustered indexes by default. There can be only one clustered index on a table, so you can specify only one unique clustered or primary key clustered constraint.
The unique and primary key constraints of create table offer a simpler alternative to the create index statement. However:
You cannot create nonunique indexes.
You cannot use all the options provided by create index.
You must drop these indexes using alter table drop constraint.
Referential integrity constraints require that data inserted into a referencing table that defines the constraint must have matching values in a referenced table. A referential integrity constraint is satisfied for either of the following conditions:
The data in the constrained columns of the referencing table contains a null value.
The data in the constrained columns of the referencing table matches data values in the corresponding columns of the referenced table.
Using the pubs2 database as an example, a row inserted into the salesdetail table (which records the sale of books) must have a valid title_id in the titles table. salesdetail is the referencing table and titles table is the referenced table. Currently, pubs2 enforces this referential integrity using a trigger. However, the salesdetail table could include this column definition and referential integrity constraint to accomplish the same task:
title_id tid references titles (title_id)
The maximum number of table references allowed for a query is 192. Use sp_helpconstraint to check a table’s referential constraints.
A table can include a referential integrity constraint on itself. For example, the store_employees table in pubs3, which lists employees and their managers, has the following self-reference between the emp_id and mgr_id columns:
emp_id id primary key, mgr_id id null references store_employees (emp_id),
This constraint ensures that all managers are also employees, and that all employees have been assigned a valid manager.
You cannot drop a referenced table until the referencing table is dropped or the referential integrity constraint is removed (unless it includes only a referential integrity constraint on itself).
Adaptive Server does not enforce referential integrity constraints for temporary tables.
To create a table that references another user’s table, you must have references permission on the referenced table. For information about assigning references permissions, see the grant command.
Table-level, referential integrity constraints appear in the create table statement as separate items. They must include the foreign key clause and a list of one or more column names.
Column names in the references clause are optional only if the columns in the referenced table are designated as a primary key through a primary key constraint.
The referenced columns must be constrained by a unique index in that referenced table. You can create that unique index using either the unique constraint or the create index statement.
The datatypes of the referencing table columns must match the datatypes of the referenced table columns. For example, the datatype of col1 in the referencing table (test_type) matches the datatype of pub_id in the referenced table (publishers):
create table test_type (col1 char (4) not null references publishers (pub_id), col2 varchar (20) not null)
The referenced table must exist when you define the referential integrity constraint. For tables that cross-reference one another, use the create schema statement to define both tables simultaneously. As an alternative, create one table without the constraint and add it later using alter table. See create schema or alter table for more information.
The create table referential integrity constraints offer a simple way to enforce data integrity. Unlike triggers, constraints cannot:
Cascade changes through related tables in the database
Enforce complex restrictions by referencing other columns or database objects
Perform “what-if” analysis
Referential integrity constraints do not roll back transactions when a data modification violates the constraint. Triggers allow you to choose whether to roll back or continue the transaction depending on how you handle referential integrity.
![]() Adaptive Server checks referential integrity constraints
before it checks any triggers, so a data modification statement
that violates the constraint does not also fire the trigger.
Adaptive Server checks referential integrity constraints
before it checks any triggers, so a data modification statement
that violates the constraint does not also fire the trigger.
When you create a cross-database constraint, Adaptive Server stores the following information in the sysreferences system table of each database:
Information stored in sysreferences |
Columns with information about the referenced table |
Columns with information about the referencing table |
|---|---|---|
Key column IDs |
refkey1 through refkey16 |
fokey1 through fokey16 |
Table ID |
reftabid |
tableid |
Database ID |
pmrydbid |
frgndbid |
Database name |
pmrydbname |
frgndbname |
You can drop the referencing table or its database. Adaptive Server automatically removes the foreign-key information from the referenced database.
Because the referencing table depends on information from the referenced table, Adaptive Server does not allow you to:
Drop the referenced table,
Drop the external database that contains the referenced table, or
Use sp_renamedb to rename either database.
You must use alter table to remove the cross-database constraint before you can do any of these actions.
Each time you add or remove a cross-database constraint, or drop a table that contains a cross-database constraint, dump both of the affected databases.
WARNING! Loading earlier dumps of databases containing cross-database constraints may cause database corruption.
The sysreferences system table stores the name and the ID number of the external database. Adaptive Server cannot guarantee referential integrity if you use load database to change the database name or to load it onto a different server.
WARNING! Before dumping a database to load it with a different name or move it to another Adaptive Server, use alter table to drop all external referential integrity constraints.
A check constraint limits the values a user can insert into a column in a table. A check constraint specifies a search_condition that any non-null value must pass before it is inserted into the table. A search_condition can include:
A list of constant expressions introduced with in
A range of constant expressions introduced with between
A set of conditions introduced with like, which can contain wildcard characters
An expression can include arithmetic operators and Transact-SQL built-in functions. The search_condition cannot contain subqueries, aggregate functions, or a host variable or parameter. Adaptive Server does not enforce check constraints for temporary tables.
A column-level check constraint can reference only the column in which it is defined; it cannot reference other columns in the table. Table-level check constraints can reference any column in the table.
create table allows multiple check constraints in a column definition.
check integrity constraints offer an alternative to using rules and triggers. They are specific to the table in which they are created, and cannot be bound to columns in other tables or to user-defined datatypes.
check constraints do not override column definitions. If you declare a check constraint on a column that allows null values, you can insert NULL into the column, implicitly or explicitly, even though NULL is not included in the search_condition. For example, if you create a check constraint specifying “pub_id in (“1389”, “0736”, “0877”, “1622”, “1756”)” or “@amount > 10000” in a table column that allows null values, you can still insert NULL into that column. The column definition overrides the check constraint.
The first time you insert a row into the table, Adaptive Server assigns the IDENTITY column a value of 1. Each new row gets a column value that is 1 higher than the last value. This value takes precedence over any defaults declared for the column in the create table statement or bound to the column with sp_bindefault.
The maximum value that can be inserted into an IDENTITY column is 10 precision - 1 for a numeric. For integer identities, it is the maximum permissible value of its type (such as 255 for tinyint, 32767 for smallint).
See Chapter 1, “System and User-Defined Datatypes” in Reference Manual: Building Blocks for more information about identifiers.
Inserting a value into the IDENTITY column allows you to specify a seed value for the column or to restore a row that was deleted in error. The table owner, database owner, or system administrator can explicitly insert a value into an IDENTITY column after using set identity_insert table_name on for the base table. Unless you have created a unique index on the IDENTITY column, Adaptive Server does not verify the uniqueness of the value. You can insert any positive integer.
You can reference an IDENTITY column using the syb_identity keyword, qualified by the table name where necessary, instead of using the actual column name.
System administrators can use the auto identity database option to automatically include a 10-digit IDENTITY column in new tables. To turn on this feature in a database, use:
sp_dboption database_name, "auto identity", "true"
Each time a user creates a table in the database without specifying a primary key, a unique constraint, or an IDENTITY column, Adaptive Server automatically defines an IDENTITY column. This column, SYB_IDENTITY_COL, is not visible when you retrieve columns with the select * statement. You must explicitly include the column name in the select list.
Server failures can create gaps in IDENTITY column values. Gaps can also occur due to transaction rollbacks, the deletion of rows, or the manual insertion of data into the IDENTITY column. The maximum size of the gap depends on the setting of the identity burning set factor and identity grab size configuration parameters, or the identity_gap value given in the create table or select into statment. See “Managing Identity Gaps in Tables” in “Creating Databases and Tables” in the Transact-SQL Users Guide.
To specify the locking scheme for a table, use the keyword lock and one of the following locking schemes:
Allpages locking, which locks data pages and the indexes affected by queries
Datapages locking, which locks only data pages
Datarows locking, which locks only data rows
If you do not specify a locking scheme, the default locking scheme for the server is used. The server-wide default is set with the configuration parameter lock scheme.
You can use alter table to change the locking scheme for a table.
The space management properties fillfactor, max_rows_per_page, exp_row_size, and reservepagegap help manage space usage for tables in the following ways:
fillfactor leaves extra space on pages when indexes are created, but the fillfactor is not maintained over time.
max_rows_per_page limits the number of rows on a data or index page. Its main use is to improve concurrency in allpages-locked tables, since reducing the number of rows can reduce lock contention. If you specify a max_rows_per_page value and datapages or datarows locking, a warning message is printed. The table is created, and the value is stored in sysindexes, but it is applied only if the locking scheme is changed later to allpages.
exp_row_size specifies the expected size of a data row. It applies only to data rows, not to indexes, and applies only to data-only-locked tables that have variable-length columns. It is used to reduce the number of forwarded rows in data-only-locked tables. It is needed mainly for tables where rows have null or short columns when first inserted, but increase in size as a result of subsequent updates. exp_row_size reserves space on the data page for the row to grow to the specified size. If you specify exp_row_size when you create an allpages-locked table, a warning message is printed. The table is created, and the value is stored in sysindexes, but it is applied only if the locking scheme is changed later to datapages or datarows.
reservepagegap specifies the ratio of empty pages to full pages to apply for commands that perform extent allocation. It applies to both data and index pages, in all locking schemes.
Table 1-14 shows the valid combinations of space management properties and locking scheme. If a create table command includes incompatible combinations, a warning message is printed and the table is created. The values are stored in system tables, but are not applied. If the locking scheme for a table changes so that the properties become valid, then they are used.
Property |
allpages |
datapages |
datarows |
|---|---|---|---|
max_rows_per_page |
Yes |
No |
No |
exp_row_size |
No |
Yes |
Yes |
reservepagegap |
Yes |
Yes |
Yes |
fillfactor |
Yes |
Yes |
Yes |
Table 1-15 shows the default values and the effects of using default values for the space management properties.
Property |
Default |
Effect of using the default |
|---|---|---|
max_rows_per_page |
0 |
Fits as many rows as possible on the page, up to a maximum of 255 |
exp_row_size |
0 |
Uses the server-wide default value, which is set with the configuration parameter default exp_row_size percent |
reservepagegap |
0 |
Leaves no empty pages during extent allocations |
fillfactor |
0 |
Fully packs leaf pages, with space left on index pages |
Commands that use large amounts of space allocate new space by allocating an extent rather than allocating single pages. The reservepagegap keyword causes these commands to leave empty pages so that subsequent page allocations happen close to the page being split or close to the page from which a row is being forwarded. Table 1-16 shows when reservepagegap is applied.
Command |
Applies to data pages |
Applies to index pages |
|---|---|---|
Fast bcp |
Yes |
Fast bcp is not used if indexes exist |
Slow bcp |
Only for heap tables, not for tables with a clustered index |
Extent allocation not performed |
select into |
Yes |
No indexes exist on the target table |
create index or alter table...constraint |
Yes, for clustered indexes |
Yes |
reorg rebuild |
Yes |
Yes |
alter table...lock (For allpages-locking to data-only locking, or vice versa) |
Yes |
Yes |
The reservepagegap value for a table is stored in sysindexes and is applied when any of the above operations on a table are executed. Use sp_chgattribute to change the stored value.
reservepagegap is not applied to worktables or sorts on worktables.
sp_help displays information about tables, listing any attributes (such as cache bindings) assigned to the specified table and its indexes, giving the attribute’s class, name, integer value, character value, and comments.
sp_depends displays information about the views, triggers, and procedures in the database that depend on a table.
sp_helpindex reports information about the indexes created on a table.
sp_helpartition reports information about the table’s partition properties.
Before you create a table with partitions, you must prepare the disk devices and segments that you will use for the partitions.
Range partitioning is dependent on sort order. If the sort order is changed, you must repartition the table for the new sort order.
Range-partition bounds must be in ascending order according to the order in which the partitions are created.
A column of text, unitext, image, or bit, Java datatype, or computed column cannot be part of a partition key, but a partitioned table can include columns with these datatypes. A composite partition key can contain up to 31 columns.
For range and hash partitions, the partition key can be a composite key with as many as 31 columns. In general, however, a table with more than four partition columns becomes hard to manage and is not useful.
Bound values for range and list partitions must be compatible with the corresponding partition key datatype. If a bound value is specified in a compatible but different datatype, Adaptive Server converts the bound value to the partition key’s datatype. Adaptive Server does not support:
Explicit conversions.
Implicit conversions that result in data loss.
NULL as a boundary in a range-partitioned table.
Conversions from nonbinary datatypes to binary or varbinary datatypes.
You can use NULL in a value list for list-partitioned tables.
You can partition a table that contains text and image columns, but partitioning has no effect on the way Adaptive Server stores the text and image columns because they reside on their own partition.
You cannot partition remote tables.
Adaptive Server considers NULL to be lower than any other partition key value for a given parition key column.
computed_column_expression can reference only columns in the same table.
The deterministic property of computed_column_expression significantly affects data operations. See “Deterministic property” in the Transact-SQL Users Guide.
Computed columns cannot have default values, and cannot be identity or timestamp columns.
You can specify nullability only for materialized computed columns. If you do not specify nullability, all computed columns are, by default, nullable. Virtual computed columns are always nullable.
Triggers and constraints, such as check, rule, unique, primary key, or foreign key) support only materialized computed columns. You cannot use them with virtual computed columns.
If a user-defined function in a computed column definition is dropped or becomes invalid, any computed column operations that call that function fail.
You can encrypt these datatypes:
int, smallint, tinyint
unsigned int, unsigned smallint, unsigned tinyint
bigint, unsigned bigint
decimal, numeric
float4, float8
money, smallmoney
date, time, smalldatetime, datetime, bigdatetime
char, varchar
unichar, univarchar
binary, varbinary
bit
The underlying datatype of encrypted data on disk is varbinary. Null values are not encrypted.
create table displays an error if you:
Specify a computed column based on an expression that references one or more encrypted columns.
Use the encrypt and compute parameters on the same column.
List an encrypted column in the partition clause
During create table, alter table, and select into operations, Adaptive Server calculates the maximum internal length of the encrypted column. The database owner must know the maximum length of the encrypted columns before he or she can make decisions about schema arrangements and page sizes.
You can create an index on an encrypted column if you specify the encryption key without any initialization vector or random padding. Adpative Server issues an error if you execute create index on an encrypted column with an initialization vector or random padding.
You can define referential integrity constraints on encrypted columns when:
Both referencing and referenced columns are encrypted.
The key you use to encrypt the columns specifies init_vector null and you have not specified pad random.
You cannot encrypt a computed column, and an encrypted column cannot appear in the expression defining a computed column. You cannot specify an encrypted column in the partition_clause of create table.
See “Encrypted Data,” in the Encrypted Columns Users Guide.
You cannot use create table on the segment that includes a virtually hashed table, since a virtually hashed table must take only one exclusive segment, which cannot be shared by other tables or databases.
Virtually hashed tables must have unique rows. Virtually hashed tables do not allow multiple rows with the same key column values because Adaptive Server cannot keep one row in the hash region and another with the same key column value in the overflow clustered region.
truncate table is not supported. Use delete from table_name instead.
SQL92 does not allow two unique constraints on a relation to have the same key columns. However, the primary key clause for a virtually hashed table is not a standard unique constraint, so you can declare a separate unique constraint with the same key columns as the virtually hashed keys.
Because you cannot create a virtually hashed clustered index after you create a table, you also cannot drop a virtually hashed clustered index.
You must create a virtually hashed table on an exclusive segment. You cannot share disk devices you assign to the segments for creating a virtually hashed table with other segments.
You cannot create two virtually hashed tables on the same exclusive segment. Adaptive Server supports 32 different segments per database. Three segments are reserved for the default, system, and log segments, so the maximum number of virtually-hashed tables per database is 29.
You cannot use the alter table or drop clustered index commands on virtually hashed tables.
Virtually hashed tables must use all-pages locking.
The key columns and hash factors of a virtually hashed table must use the int datatype.
You cannot include text or image columns in virtually hashed tables, or columns with datatypes based on the text or image datatypes.
You cannot create a partitioned virtually hashed table.
Table-level logging settings defined by create table also apply to tables created via select into.
Although you can create tables with minimal logging in databases using full durability, the databases do not use minimal logging for these tables. Adaptive Server allows you to set these tables to minimal logging so you can use these databases as templates for other databases with durability set to no_recovery, where minimal logging takes effect in the dependent database.
You can keep the hash factor for the first key as 1. The hash factor for all the remaining key columns is greater than the maximum value of the previous key allowed in the hash region multiplied by its hash factor.
Adaptive Server allows tables with hash factors greater than 1 for the first key column to have fewer rows on a page. For example, if a table has a hash factor of 5 for the first key column, after every row in a page, space for the next four rows is kept empty. To support this, Adaptive Server requires five times the amount of table space.
If the value of a key column is greater than or equal to the hash factor of the next key column, the current row is inserted in the overflow clustered region to avoid collisions in the hash region.
For example, t is a virtually hashed table with key columns id and age, and corresponding hash factors of (10,1). Because the hash value for rows (5, 5) and (2, 35) is 55, this may result in a hash collision.
However, because the value 35 is greater than or equal to 10 (the hash factor for the next key column, id), Adaptive Server stores the second row in the overflow clustered region, avoiding collisions in the hash region.
In another example, if u is a virtually hashed table with a primary index and hash factors of (id1, id2, id3) = (125, 25, 5) and a max hash_value of 200:
Row (1,1,1) has a hash value of 155 and is stored in the hash region.
Row (2,0,0) has a hash value 250 and is stored in overflow clustered region.
Row (0,0,6) has a hash factor of 6 x 5, which is greater than or equal to 25, so it is stored in the overflow clustered region.
Row (0,7,0) has a hash factor of 7 x 25, which is greater than or equal to 125, so it is stored in the overflow clustered region
You cannot include a referential integrity constraint that references a column on a local temporary database unless it is from a table on the same local temporary database. create table fails if it attempts to create a reference to a column on a local temporary database from a table in another database.
You cannot encrypt a column with an encryption key stored in a local temporary database unless the column’s table resides on the same local temporary database. alter table fails if it attempts to encrypt a column with an encryption key on the local temporary database and the table is in another database.
If Java is enabled in the database, you can create tables with Java-SQL columns. Refer to Java in Adaptive Server Enterprise for detailed information.
The declared class (datatype) of the Java-SQL column must implement either the Serializable or Externalizable interface.
When you create a table, you cannot specify a Java-SQL column:
As a foreign key
In a references clause
As having the UNIQUE property
As the primary key
If in row is specified, the value stored cannot exceed 16K bytes, depending on the page size of the database server and other variables.
If off row is specified:
The column cannot be referenced in a check constraint.
The column cannot be referenced in a select that specifies distinct.
The column cannot be specified in a comparison operator, in a predicate, or in a group by clause.
ANSI SQL – Compliance level: Entry-level compliant.
Transact-SQL extensions include:
Use of a database name to qualify a table or column name
IDENTITY columns
The not null column default
The asc and desc options
The reservepagegap option
The lock clause
The on segment_name clause
See Chapter 1, “System and User-Defined Datatypes”of Reference Manual: Building Blocks for datatype compliance information.
Any user can create temporary tables and new tables with logging disabled.
The following describes permission checks for create table that differ based on your granular permissions settings.
Granular permissions enabled |
With granular permissions enabled, you must have the create table privilege. You must have create any table to run create table for other users. |
Granular permissions disabled |
With granular permissions disabled, you must be the database owner , a user with sa_role, or a user with create table privilege. |
Values in event and extrainfo columns of sysaudits are:
Event |
Audit option |
Command or access audited |
Information in extrainfo |
|---|---|---|---|
10 |
create |
create table |
|
Commands alter table, create existing table, create index, create rule, create schema, create view, drop index, drop rule, drop table
System procedures sp_addmessage, sp_addsegment, sp_addtype, sp_bindmsg, sp_chgattribute, sp_commonkey, sp_depends, sp_foreignkey, sp_help, sp_helpjoins, sp_helpsegment, sp_primarykey, sp_rename, sp_spaceused
