![]()
![]()
![]()
![]()
Makes a backup copy of the entire database, including the transaction log, in a form that can be read in with load database. Dumps and loads are performed through Backup Server.
The target platform of a load database operation need not be the same platform as the source platform where the dump database operation occurred. dump database and load database are performed from either a big endian platform to a little endian platform, or from a little endian platform to a big endian platform.
See Tivoli Storage Manager only for dump database syntax when the Tivoli Storage Manager is licensed at your site.
dump database database_name
to [compress::[compression_level::]]stripe_device
[at backup_server_name]
[density = density_value,
blocksize = number_bytes,
capacity = number_kilobytes,
dumpvolume = volume_name,
file = file_name]
with verify[= header | full]
[stripe on [compress::[compression_level::]]stripe_device
[at backup_server_name]
[density = density_value,
blocksize = number_bytes,
capacity = number_kilobytes,
dumpvolume = volume_name,
file = file_name]]
[[stripe on [compress::[compression_level::]]stripe_device
[at backup_server_name]
[density = density_value,
blocksize = number_bytes,
capacity = number_kilobytes,
dumpvolume = volume_name,
file = file_name]]...]
[with {
density = density_value,
blocksize = number_bytes,
capacity = number_kilobytes,
compression = compress_level
dumpvolume = volume_name,
file = file_name,
[dismount | nodismount],
[nounload | unload],
passwd = password,
retaindays = number_days,
[noinit | init],
notify = {client | operator_console}
}]
Tivoli Storage Manager only Use this syntax for copying the database when the Tivoli Storage Manager provides backup services.
dump database database_name
to "syb_tsm::object_name"
[blocksize = number_bytes]
[stripe on "[syb_tsm::]object_name"
[blocksize = number_bytes]]...]
[with {
blocksize = number_bytes,
compression = compress_level,
passwd = password,
[noinit | init],
notify = {client | operator_console},
verify[ = header | full]
} ]
is the name of the database from which you are copying data. The database name can be specified as a literal, a local variable, or a stored procedure parameter.
is a number between 0 and 9, 100, or 101. For single-digit compression levels, 0 indicates no compression, and 9 provides the highest level of compression. Compression levels of 100 and 101 provide a faster, more efficient compression mode, with 100 providing faster compression and 101 providing better compression. If you do not specify compression_level, Adaptive Server does not compress the dump.
See Chapter 28, “Backing Up and Restoring User Databases” in the System Administration Guide for more information about the compress option.
![]() Sybase recommends the native "compression = compress_level" option
as preferred over the older "compress::compression_level" option.
The native option allows compression of both local and remote dumps,
and the dumps that it creates will describe their own compression
level during a load. The older option is retained for compatibility
with older applications.
Sybase recommends the native "compression = compress_level" option
as preferred over the older "compress::compression_level" option.
The native option allows compression of both local and remote dumps,
and the dumps that it creates will describe their own compression
level during a load. The older option is retained for compatibility
with older applications.
is the device to which to copy the data. See “Specifying dump devices” in this section for information about what form to use when specifying a dump device.
is the name of the Backup Server. Do not specify this parameter when dumping to the default Backup Server. Specify this parameter only when dumping over the network to a remote Backup Server. You can specify as many as 32 remote Backup Servers with this option. When dumping across the network, specify the network name of a remote Backup Server running on the machine to which the dump device is attached. For platforms that use interfaces files, the backup_server_name must appear in the interfaces file.
overrides the default density for a tape device. Valid densities are 800, 1600, 6250, 6666, 10000, and 38000. Not all values are valid for every tape drive; use the correct density for your tape drive.
overrides the default block size for a dump device. The block size must be at least one database page (2048 bytes for most systems) and must be an exact multiple of the database page size. For optimal performance, specify the blocksize as a power of 2, for example, 65536, 131072, or 262144.
is the maximum amount of data that the device can write to a single tape volume. The capacity must be at least five database pages and should be less than the recommended capacity for your device.
A general rule for calculating capacity is to use 70 percent of the manufacturer’s maximum capacity for the device, allowing 30 percent for overhead such as record gaps and tape marks. The maximum capacity is the capacity of the device on the drive, not the drive itself. This rule works in most cases, but may not work in all cases due to differences in overhead across vendors and across devices.
On UNIX platforms that cannot reliably detect the end-of-tape marker, indicate how many kilobytes can be dumped to the tape. You must supply a capacity for dump devices specified as a physical path name. If a dump device is specified as a logical device name, the Backup Server uses the size parameter stored in the sysdevices system table unless you specify a capacity.
is a number between 0 and 9, 100, or 101. For single-digit compression levels, 0 indicates no compression, and 9 provides the highest level of compression. Compression levels of 100 and 101 provide a faster, more efficient compression mode, with 100 providing faster compression and 101 providing better compression. If you do not specify compression_level, Adaptive Server does not compress the dump.
![]() Sybase recommends the native "compression = compress_level" option
as preferred over the older "compress::compression_level" option.
The native option allows compression of both local and remote dumps,
and the dumps that it creates will describe their own compression
level during a load. The older option is retained for compatibility
with older applications.
Sybase recommends the native "compression = compress_level" option
as preferred over the older "compress::compression_level" option.
The native option allows compression of both local and remote dumps,
and the dumps that it creates will describe their own compression
level during a load. The older option is retained for compatibility
with older applications.
establishes the name that is assigned to the volume. The maximum length of volume_name is 6 characters. Backup Server writes the volume_name in the ANSI tape label when overwriting an existing dump, dumping to a new tape, or dumping to a tape whose contents are not recognizable. The load database command checks the label and generates an error message if the wrong volume is loaded.
WARNING! Label each tape volume as you create it so that the operator can load the correct tape.
allows the backupserver to perform a minimal header or structural row check on the data pages as they are being copied to the archives. There are no structural checks done at this time to gam, oam, allocation pages, indexes, text, or log pages. The only other check is done on pages where the page number matches to the page header.
is an additional dump device. You can use as many as 32 devices, including the device named in the to stripe_device clause. The Backup Server splits the database into approximately equal portions, and sends each portion to a different device. Dumps are made concurrently on all devices, reducing the time required to make a dump and requiring fewer volume changes during the dump. See “Specifying dump devices” for information about how to specify a dump device.
on platforms that support logical dismount, determines whether tapes remain mounted. By default, all tapes used for a dump are dismounted when the dump completes. Use nodismount to keep tapes available for additional dumps or loads.
determines whether tapes rewind after the dump completes. By default, tapes do not rewind, allowing you to make additional dumps to the same tape volume. Specify unload for the last dump file to be added to a multidump volume. This rewinds and unloads the tape when the dump completes.
is the password you provide to protect the dump file from unauthorized users. The password must be between 6 and 30 characters long. You cannot use variables for passwords. For rules on passwords, see Chapter 14, “Managing Adaptive Server Logins, Database Users, and Client Connections,” in the System Administration Guide, Volume 1.
on UNIX systems – when dumping to disk, specifies the number of days that Backup Server protects you from overwriting the dump. If you try to overwrite the dump before it expires, Backup Server requests confirmation before overwriting the unexpired volume.
![]() This option is meaningful only when dumping to a disk.
It is not meaningful for tape dumps.
This option is meaningful only when dumping to a disk.
It is not meaningful for tape dumps.
The number_days must be a positive integer or 0, for dumps that you can overwrite immediately. If you do not specify a retaindays value, Backup Server uses the tape retention in days value set by sp_configure.
determines whether to append the dump to existing dump files or reinitialize (overwrite) the tape volume. By default, Adaptive Server appends dumps following the last end-of-tape mark, allowing you to dump additional databases to the same volume. New dumps can be appended only to the last volume of a multivolume dump. Use init for the first database you dump to a tape to overwrite its contents.
Use init when you want Backup Server to store or update tape device characteristics in the tape configuration file. For more information, see the System Administration Guide.
is the name of the dump file. The name cannot exceed 17 characters and must conform to operating system conventions for file names. For more information, see “Dump files”.
overrides the default message destination.
On operating systems that offer an operator terminal feature, volume change messages are always sent to the operator terminal on the machine on which Backup Server is running. Use client to route other Backup Server messages to the terminal session that initiated the dump database.
On operating systems that do not offer an operator terminal feature, such as UNIX, messages are sent to the client that initiated the dump database. Use operator_console to route messages to the terminal on which Backup Server is running.
is the keyword that invokes the libsyb_tsm.so module that enables communication between Backup Server and Tivoli Storage Manager.
is the name of the backup object on TSM server.
Dumps the database pubs2 to a tape device. If the tape has an ANSI tape label, this command appends this dump to the files already on the tape, since the init option is not specified:
dump database pubs2 to "/dev/nrmt0"
For UNIX – dumps the pubs2 database, using the REMOTE_BKP_SERVER Backup Server. The command names three dump devices, so the Backup Server dumps approximately one-third of the database to each device. This command appends the dump to existing files on the tapes. On UNIX systems, the retaindays option specifies that the tapes cannot be overwritten for 14 days:
dump database pubs2 to "/dev/rmt4" at REMOTE_BKP_SERVER stripe on "/dev/nrmt5" at REMOTE_BKP_SERVER stripe on "/dev/nrmt0" at REMOTE_BKP_SERVER with retaindays = 14
The init option initializes the tape volume, overwriting any existing files:
dump database pubs2 to "/dev/nrmt0" with init
Rewinds the dump volumes upon completion of the dump:
dump database pubs2 to "/dev/nrmt0" with unload
For UNIX – the notify clause sends Backup Server messages requesting volume changes to the client which initiated the dump request, rather than sending them to the default location, the console of the Backup Server machine:
dump database pubs2 to "/dev/nrmt0" with notify = client
Creates a compressed dump of the pubs2 database into a local file called dmp090100.dmp using a compression level of 4:
dump database pubs2 to "compress::4::/opt/bin/Sybase/dumps/dmp090100.dmp"
Alternatively, you can create a compressed dump of the pubs2 database into a local file called dmp090100.dmp using a compression level of 100 using compression = compression_level syntax
dump database pubs2 to "/opt/bin/Sybase/dumps/dmp090100.dmp" with compression = 100
Dumps the pubs2 database to the remote machine called “remotemachine” and uses a compression level of 4:
dump database pubs2 to "/Syb_backup/mydb.db" at remotemachine with compression = "4"
Dumps the pubs2 database to the TSM backup object “obj1.1”.
dump database pubs2 to "syb_tsm::obj1.1"
Dumps the pubs2 database to the TSM backup object “obj1.2” using multiple stripes.
dump database pubs2 to "syb_tsm::obj1.2" stripe on "syb_tsm::obj1.2" stripe on "syb_tsm::obj1.2" stripe on "syb_tsm::obj1.2" stripe on "syb_tsm::obj1.2"
If you use sp_hidetext followed by a cross-platform dump and load, you must manually drop and re-create all hidden objects.
dump database executes in three phases. A progress message informs you when each phase completes. When the dump is finished, it reflects all changes that were made during its execution, except for those initiated during phase 3.
Table 1-22 describes the commands and system procedures used to back up databases:
To do this |
Use this command |
|---|---|
Make routine dumps of the entire database, including the transaction log. |
dump database |
Make routine dumps of the transaction log, then truncate the inactive portion. |
dump transaction |
Dump the transaction log after failure of a database device. |
dump transaction with no_truncate |
Truncate the log without making a backup, then copy the entire database. |
dump transaction with truncate_only dump database |
Truncate the log after your usual method fails due to insufficient log space, then copy the entire database. |
dump transaction with no_log dump database |
Respond to the Backup Server volume change messages. |
sp_volchanged |
If a database has proxy tables, the proxy tables are a part of the database save set. The content data of proxy tables is not included in the save; only the pointer is saved and restored.
You cannot dump from an 11.x Adaptive Server to a 10.x Backup Server.
You cannot mix Sybase dumps and non-Sybase data (for example, UNIX archives) on the same tape.
If a database has cross-database referential integrity constraints, the sysreferences system table stores the name—not the ID number—of the external database. Adaptive Server cannot guarantee referential integrity if you use load database to change the database name or to load it onto a different server.
WARNING! Before dumping a database to load it with a different name or move it to another Adaptive Server, use alter table to drop all external referential integrity constraints.
You cannot use dump database in a user-defined transaction.
If you issue dump database on a database where a dump transaction is already in progress, dump database sleeps until the transaction dump completes.
When using 1/4-inch cartridge tape, you can dump only one database or transaction log per tape.
You cannot dump a database if it has offline pages. To force offline pages online, use sp_forceonline_db or sp_forceonline_page.
Before you run dump database, for a cross platform dump and load, use the following procedures to move the database to a transactional quiescent status:
Verify the database runs cleanly by executing dbcc checkdb and dbcc checkalloc.
To prevent concurrent updates from open transactions by other processes during dump database, use sp_dboption to place the database in a single- user mode.
Flush statistics to systabstats using sp_flushstats.
Wait for 10 to 30 seconds, depending on the database size and activity.
Run checkpoint against the database to flush updated pages.
Run dump database.
dump transaction and load transaction are not allowed across platforms.
dump database and load database to or from a remote backupserver are not supported across platforms.
You cannot load a password-protected dump file across platforms.
If you perform dump database and load database for a parsed XML object, you must parse the text again after the load database is completed.
You cannot perform dump database and load database across platforms on Adaptive Servers versions earlier than 11.9.
Adaptive Server cannot translate embedded data structures stored as binary, varbinary, or image columns.
load database is not allowed on the master database across platforms.
Stored procedures and other compiled objects are recompiled from the SQL text in syscomments at the first execution after the load database.
If you do not have permission to recompile from text, then the person who does has to recompile from text using dbcc upgrade_object to upgrade objects.
![]() If you migrate login records in syslogins system
table in the master database from Solaris to Linux, you can use bcp with
character format. The login password from the Solaris platform is
compatible on Linux without a trace flag from this release. For
all other combinations and platforms, login records need to be re-created
because the passwords are not compatible.
If you migrate login records in syslogins system
table in the master database from Solaris to Linux, you can use bcp with
character format. The login password from the Solaris platform is
compatible on Linux without a trace flag from this release. For
all other combinations and platforms, login records need to be re-created
because the passwords are not compatible.
Adaptive Server database dumps are dynamic—they can take place while the database is active. However, they may slow the system down slightly, so you may want to run dump database when the database is not being heavily updated.
Back up the master database regularly and frequently. In addition to your regular backups, dump master after each create database, alter database, and disk init command is issued.
Back up the model database each time you make a change to the database.
Use dump database immediately after creating a database, to make a copy of the entire database. You cannot run dump transaction on a new database until you have run dump database.
Each time you add or remove a cross-database constraint or drop a table that contains a cross-database constraint, dump both of the affected databases.
WARNING! Loading earlier dumps of these databases can cause database corruption.
Develop a regular schedule for backing up user databases and their transaction logs.
Use thresholds to automate backup procedures. To take advantage of Adaptive Server last-chance threshold, create user databases with log segments on a device that is separate from data segments. For more information about thresholds, see the System Administration Guide.
The master, model, and sybsystemprocs databases do not have separate segments for their transaction logs. Use dump transaction with truncate_only to purge the log, then use dump database to back up the database.
Backups of the master database are needed for recovery procedures in case of a failure that affects the master database. See the System Administration Guide for step-by-step instructions for backing up and restoring the master database.
If you are using removable media for backups, the entire master database must fit on a single volume unless you have another Adaptive Server that can respond to volume change messages.
You can specify the dump device as a literal, a local variable, or a parameter to a stored procedure.
You cannot dump to the null device (on UNIX, /dev/null ).
Dumping to multiple stripes is supported for tape and disk devices. Placing multiple dumps on a device is supported only for tape devices.
You can specify a local dump device as:
A logical device name from the sysdevices system table
An absolute path name
A relative path name
Backup Server resolves relative path names using the current working directory in Adaptive Server.
When dumping across the network, you must specify the absolute path name of the dump device. The path name must be valid on the machine on which Backup Server is running. If the name includes any characters except letters, numbers, or the underscore (_), you must enclose it in quotes.
Ownership and permissions problems on the dump device may interfere with the use of dump commands. sp_addumpdevice adds the device to the system tables, but does not guarantee that you can dump to that device or create a file as a dump device.
You can run more than one dump (or load) at the same time, as long as each uses different dump devices.
If the device file already exists, Backup Server overwrites it; it does not truncate it. For example, suppose you dump a database to a device file and the device file becomes 10MB. If the next dump of the database to that device is smaller, the device file is still 10MB.
If you issue a dump command without the init qualifier and Backup Server cannot determine the device type, the dump command fails. For more information, see the System Administration Guide.
You must have a Backup Server running on the same machine as Adaptive Server. The Backup Server must be listed in the master..sysservers table. This entry is created during installation or upgrade; do not delete it.
If your backup devices are located on another machine so that you dump across a network, you must also have a Backup Server installed on the remote machine.
Dumping a database with the init option overwrites any existing files on the tape or disk.
If you perform two or more dumps to a tape device and use the same file name for both dumps (specified with the FILENAME parameter), Adaptive Server appends the second dump to the archive device. You will not be able to restore the second dump because Adaptive Server locates the first instance of the dump image with the specified file name and restores this image instead. Adaptive Server does not search for subsequent dump images with the same file name.
Backup Server sends the dump file name to the location specified by the with notify clause. Before storing a backup tape, the operator should label it with the database name, file name, date, and other pertinent information. When loading a tape without an identifying label, use the with headeronly and with listonly options to determine the contents.
The name of a dump file identifies the database that was dumped and when the dump was made. However, in the syntax, file_name has different meanings depending on whether you are dumping to disk or to a UNIX tape:
file = file_name
In a dump to disk, the path name of a disk file is also its file name.
In a dump to a UNIX tape, the path name is not the file name. The ANSI Standard Format for File Interchange contains a file name field in the HDR1 label. For tapes conforming to the ANSI specification, this field in the label identifies the file name. The ANSI specification applies these labels only to tape; it does not apply to disk files.
This creates two problems:
UNIX does not follow the ANSI convention for tape file names. UNIX considers the tape’s data to be unlabeled. Although it can be divided into files, those files have no name.
In Backup Server, the ANSI tape labels are used to store information about the archive, negating the ANSI meanings. Therefore, disk files also have ANSI labels, because the archive name is stored there.
The meaning of filename changes depending on the kind of dump you are performing. For example, in the following syntax:
dump database database_name to 'filename' with file='filename'
The first filename refers to the path name you enter to display the file.
The second filename is actually the archive name, the name stored in the HDR1 label in the archive, which the user can specify with the file=filename parameter of the dump or load command.
When the archive name is specified, the server uses that name during a database load to locate the selected archive.
If the archive name is not specified, the server loads the first archive it encounters.
In both cases, file='archivename' establishes the name that is stored in the HDR1 label, and which the subsequent load uses to validate that it is looking at the correct data.
If the archive name is not specified, a dump creates one; a load uses the first name it encounters.
The meaning of filename in the to ’filename’ clause changes according to whether this is a disk or tape dump:
If the dump is to tape, ‘filename’ is the name of the tape device,
If the dump is to disk, it is the name of a disk file.
If this is a disk dump and ‘filename’ is not a complete path, it is modified by prepending the server’s current working directory.
If you are dumping to tape and you do not specify a file name, Backup Server creates a default file name by concatenating the following:
Last seven characters of the database name
Two-digit year number
Three-digit day of the year (1–366)
Hexadecimal-encoded time at which the dump file was created
For example, the file cations980590E100 contains a copy of the publications database made on the 59th day of 1998:
Figure 1-4: File naming convention for database dumps to tape
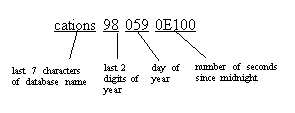
Dump volumes are labeled according to the ANSI tape-labeling standard. The label includes the logical volume number and the position of the device within the stripe set.
During loads, Backup Server uses the tape label to verify that volumes are mounted in the correct order. This allows you to load from a smaller number of devices than you used at dump time.
![]() When dumping and loading across the network, you must
specify the same number of stripe devices for each operation.
When dumping and loading across the network, you must
specify the same number of stripe devices for each operation.
On UNIX systems – Backup Server requests a volume change when the tape capacity has been reached. After mounting another volume, the operator notifies Backup Server by executing sp_volchanged on any Adaptive Server that can communicate with Backup Server.
If Backup Server detects a problem with the currently mounted volume, it requests a volume change by sending messages to either the client or its operator console. The operator responds to these messages with the sp_volchanged system procedure.
By default (noinit), Backup Server writes successive dumps to the same tape volume, making efficient use of high-capacity tape media. Data is added following the last end-of-tape mark. New dumps can be appended only to the last volume of a multivolume dump. Before writing to the tape, Backup Server verifies that the first file has not yet expired. If the tape contains non-Sybase data, Backup Server rejects it to avoid destroying potentially valuable information.
Use the init option to reinitialize a volume. If you specify init, Backup Server overwrites any existing contents, even if the tape contains non-Sybase data, the first file has not yet expired, or the tape has ANSI access restrictions.
Figure 1-5 illustrates how to dump three databases to a single volume using:
Database dumps from a 32-bit version of Adaptive Server are fully compatible with a 64-bit version of Adaptive Server of the same platform, and vice-versa.
At the beginning of a dump database, Adaptive Server passes Backup Server the primary device name of all database and log devices. If the primary device has been unmirrored, Adaptive Server passes the name of the secondary device instead. If any named device fails before the Backup Server completes its data transfer, Adaptive Server aborts the dump.
If a user attempts to unmirror any of the named database devices while a dump database is in progress, Adaptive Server displays a message. The user executing the disk unmirror command can abort the dump or defer the disk unmirror until after the dump is complete.
Due to the design of indexes within a dataserver that provides an optimum search path, index rows are ordered for fast access to the table's data row. Index rows which contain row identifiers (RIDs), are treated as binary to achieve a fast access to the user table.
Within the same architecture platform, the order of index rows remains valid and search order for a selection criteria takes its normal path. However, when index rows are translated across different architectures, this invalidates the order by which optimization was done. This results in an invalid index on user tables when the cross platform dump and load feature is performed.
A database dump from a different architecture, such as big endian to little endian, is loaded, certain indexes are marked as suspect:
Non-clustered index on APL table.
Clustered index on DOL table.
Non-clustered index on DOL table.
To fix indexes on the target system, after load from a different architecture dump, you could use one of two methods:
Drop and re-create all of the indexes.
Use sp_post_xpload, see Chapter 1, “System Procedures,” in Reference Manual: Procedures.
Since the data point and information varies from usage on indexes, the schema, user data, number of indexes, index key length, and number of index rows, in general, it requires planning to recreate indexes on large tables as it can be a lengthy process. sp_post_xpload validates indexes, drops invalid indexes, and recreates dropped indexes, in a single command on databases.
Since sp_post_xpload performs many operations it can take longer than drop and recreate indexes. Sybase recommends that you use the drop and recreate indexes on those databases larger that 10G..
To use a compressed dump for an archive database, you must:
Create the compressed dump with the with compression = <compression level> option of the dump database or dump tran command.
Create a memory pool for accessing the archive database.
![]() Dumps generated with “compress::” cannot
be loaded into an archive database. Therefore, any references to
compression in this chapter refer to dumps generated using the with
compression = <compression level> option.
Dumps generated with “compress::” cannot
be loaded into an archive database. Therefore, any references to
compression in this chapter refer to dumps generated using the with
compression = <compression level> option.
You cannot load dumps generated with “compress::” into an archive database. There are no compatibility issues with dumps using this compression option on traditional databases.
The format of a compressed dump generated with the with compression = compression_level option has changed. Backup Server versions 15.0 ESD #2 and later is the component that writes the new compression format. Therefore:
A compressed dump made using a Backup Server version 15.0 ESD #2 and later can be loaded only into a pre-15.0 ESD #2 installation using a Backup Server version 15.0 ESD #2 or later.
If you are using a pre-15.0 ESD #2 installation and want to use your dumps for an archive database, use Backup Server version 15.0 ESD #2 or higher to create compressed database dumps.
![]() A Backup Server version 15.0 ESD #2 and later
understands both 15.0 ESD #2 and earlier compression formats;
therefore, you can use a 15.0 ESD #2 Backup Server for
both dump and loads.
A Backup Server version 15.0 ESD #2 and later
understands both 15.0 ESD #2 and earlier compression formats;
therefore, you can use a 15.0 ESD #2 Backup Server for
both dump and loads.
dump and load work on the ciphertext of encrypted columns. This behavior ensures that the data for encrypted columns remains encrypted while on disk.
dump and load pertain to the whole database. Default keys and keys created in the same database are dumped and loaded along with the data to which they pertain.
If your keys are in a separate database from the columns they encrypt, Sybase recommends that:
When you dump the database containing encrypted columns, you also dump the database where the key was created. This is necessary if new keys have been added since the last dump.
When you dump the database containing an encryption key, dump all databases containing columns encrypted with that key. This keeps the encrypted data in sync with the available keys.
After loading the database containing the encryption keys and the database containing the encrypted columns, bring both databases on line at the same time.
Because of metadata dependencies of encrypted columns on the key’s database, follow the steps below if you intend to load the key database into a database with a different name (if your data is stored in the same database as your keys, you need not follow these steps):
Before dumping the database containing the encrypted columns, use alter table to decrypt the data.
Dump the databases containing keys and encrypted columns.
After loading the databases, use alter table to re-encrypt the data with the keys in the newly-named database.
The consistency issues between encryption keys and encrypted columns are similar to those for cross-database referential integrity. See “Cross-database constraints and loading databases” in the System Administration Guide.
See THE TSM BOOK for more information about creating backups when TSM is supported at your site.
ANSI SQL – Compliance level: Transact-SQL extension.
Only the System Administrator, the Database Owner, and users with the Operator role can execute dump database.
Values in event and extrainfo columns of sysaudits are:
Event |
Audit option |
Command or access audited |
Information in extrainfo |
|---|---|---|---|
34 |
dump |
dump database |
|
Documents Chapter 28, “Backing Up and Restoring User Databases” in the System Administration Guide.
Commands dump transaction, load database, load transaction
System procedures sp_addthreshold, sp_addumpdevice, sp_dropdevice, sp_dropthreshold, sp_helpdb, sp_helpdevice, sp_helpthreshold, sp_hidetext, sp_logdevice, sp_spaceused, sp_volchanged