![]()
![]()
![]()
![]()
The Turkish language has two forms of what appears to be the letter I. One form, referred to as I-dot, appears as the following:
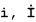
The second form, referred to as I-no-dot, appears as the following:
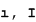
Even though these letters appear as variations of the same letter, in the Turkish alphabet they are considered to be distinct letters. SQL Anywhere provides the Turkish collation 1254TRK to support these variations.
Turkish rules for case conversion of these characters are incompatible with ANSI SQL standard rules for case conversion. For
example, Turkish says that the lowercase equivalent of I is:
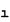
However, the ANSI standard says that it is:
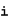
For this reason, correct case-insensitive matching is dependent on whether the text being matched is Turkish or English/ANSI. In many contexts, there is not enough information to make such a distinction, which leads to some non-standard behaviors in such databases.
For example, consider the following statements, executed against a database using the 1254TRK collation:
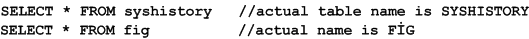
The first statement references a system object, and ANSI SQL conversion rules are required to match the name. The second statement references a user object, and Turkish conversion rules are required to match the name. However, the database server cannot tell which conversion rules to use until it knows what the object is, and it cannot know what the object is until it knows what conversion rules to use. The situation cannot be resolved properly for both system and user objects. In this example, since the database server is using the Turkish collation 1254TRK, the first statement fails because lowercase I is not considered equivalent to uppercase I. The second statement succeeds.
The incompatibility of Turkish and ANSI standards requires that system object references in Turkish databases specify the object name in the correct case, that is, the case used to create the object. The first statement above should be written as follows:
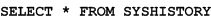
In fact, only the letter I must be in the correct case.
As an alternative, it is acceptable, although unusual, to write the statement as follows:
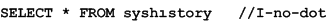
Note that keywords such as INSERT are case-insensitive even in Turkish databases. SQL Anywhere knows that all keywords use only English letters, so it uses ANSI case conversion rules when matching keywords. SQL Anywhere also applies this knowledge for certain other identifiers, such as built-in functions. However, objects whose names are stored in the catalog must be specified using the correct case or letter, as described above. To determine the correct case, look in the system view that defines the system object. See System views.
Data in case-insensitive Turkish databases
Alternative Turkish collation 1254TRKALT
 |
Discuss this page in DocCommentXchange.
|
Copyright © 2010, iAnywhere Solutions, Inc. - SQL Anywhere 12.0.0 |