![]()
![]()
![]()
![]()
Nested-loop joins provide efficient access when tables are indexed on join columns. The process of creating the result set for a nested-loop join is to nest the tables, and to scan the inner tables repeatedly for each qualifying row in the outer table, as shown in Figure 6-1.
Figure 6-1: Nesting of tables during a nested-loop join
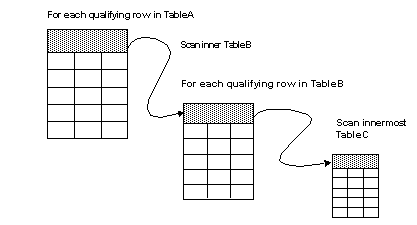
In Figure 6-1, the access to the tables to be joined is nested:
TableA is accessed once. If the table has no useful indexes, a table scan is performed. If an index can reduce I/O costs, the index is used to locate the rows.
TableB is accessed once for each qualifying row in TableA. If 15 rows from TableA match the conditions in the query, TableB is accessed 15 times. If TableB has a useful index on the join column, it might require 3 I/Os to read the data page for each scan, plus one I/O for each data page. The cost of accessing TableB would be 60 logical I/Os.
TableC is accessed once for each qualifying row in TableB each time TableB is accessed. If 10 rows from TableB match for each row in TableA, then TableC is scanned 150 times. If each access to TableC requires 3 I/Os to locate the data row, the cost of accessing TableC is 450 logical I/Os.
If TableC is small, or has a useful index, the I/O count stays reasonably small. If TableC is large and has no useful index on the join columns, the optimizer may choose to use a sort-merge join or the reformatting strategy to avoid performing extensive I/O.
