![]()
![]()
![]()
![]()
Adaptive Server accesses data in parallel in different ways, depending configuration parameter settings, table partitioning, and the availability of indexes. The optimizer may choose a mix of serial and parallel methods for queries that involve multiple tables or multiple steps. Parallel methods include:
Hash-based table scans
Hash-based nonclustered index scans
Partition-based scans, either full table scans or scans positioned with a clustered index
Range-based scans during merge joins
The following sections describe some of the methods.
For more examples, see Chapter 8, “Parallel Query Optimization.”
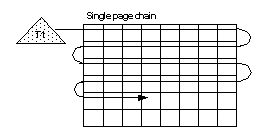
Figure 7-3 shows a scan on an allpages-locked table executed in serial by a single task. The task follows the table’s page chain to read each page, stopping to perform physical I/O when needed pages are not in the cache.
Figure 7-3: A serial task scans data pages