![]()
![]()
![]()
![]()
The Java community has made robust XML parsers available to developers for free, and Sun Microsystems has even defined a standard set of Java APIs for XML Parsing (JAXP). JAXP provides a straightforward API for developers to load DOM or Simple API for XML (SAX) XML parsers, and each parser provides methods that allow a developer to access the content of any XML document.
Each of these parser APIs offer its own strengths. Document Object Model (DOM) parsers allow developers to load the data of an entire XML document into memory, and provide powerful features to allow developers to modify the document while it is in memory. Using DOM, developers can both deserialize XML (read a document into in-memory objects) and serialize XML (for example, write a document out to disk). In contrast, because SAX XML parsers are read-only you do not use them to build a new XML document. The SAX event-based parser is faster and consumes far less memory than the DOM parser; consequently, it allows developers to parse the data out of an XML document more effectively.
While these parsers are powerful tools, both are limited in their ability to handle the data in XML documents productively. Although the SAX parser is efficient, when a parse is complete, the only data remaining for an application’s use is that which the developer wrote custom code to store. This is acceptable if the developer wants access to only one or two pieces of data in the document and does not mind writing SAX callbacks to capture and store the relevant data in some other custom objects they wrote. But because the document data is not stored in memory, it can require a lot of code on the developer’s part to perform data processing on the document (for example, calculating the total dollar value of a series of order line items). The developer can easily use the DOM parser to store the XML document in memory and provide Java APIs to navigate through the document. Unfortunately, the interface to every single XML document is identical in DOM, as shown in Figure 1-1.
Figure 1-1: DOM’s generic representation of unique documents
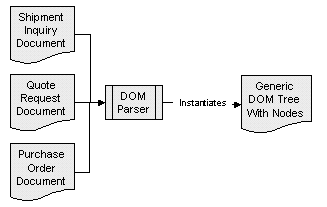
The DOM parse tree makes every document look the same from a programming API perspective: A request for quote, a purchase order, and a shipping inquiry appear identical to the developer. A purchase order has a reference number, customer information, payment terms, and a list of items being ordered—not generalized document objects, like nodes, node lists, node maps, and so on. This generic abstraction limits developer productivity: Java objects are most valuable when they have some resemblance to the physical entity being modeled.
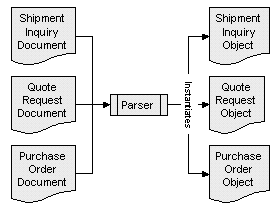
An ideal solution would be to represent the specific document hierarchy in a corresponding object hierarchy, without requiring months of developer time to achieve the kind of useful data abstraction that permits the rest of the application to be developed quickly. This solution is shown in Figure 1-2.
Figure 1-2: Document to object hierarchy mapping