![]()
![]()
![]()
![]()
Distributed database systems allow client applications to access data on multiple database servers throughout an enterprise—even geographically dispersed enterprises. Replication Server ensures that data on replicate databases stays updated while off-loading processing responsibilities from the source database.
As Figure 1-1 illustrates, these enterprises may consist of many LANs and one or more WANs.
Figure 1-1: Replication system in a distributed environment
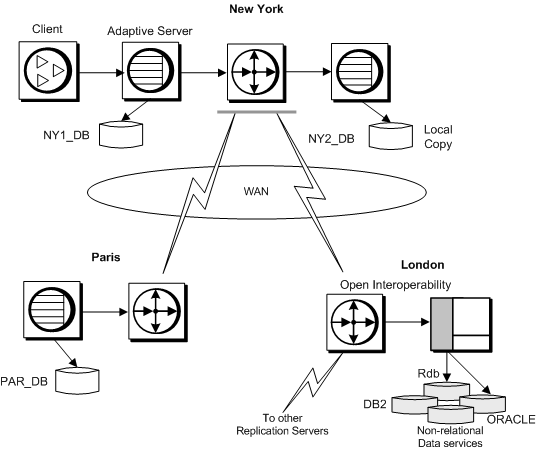
Replication Server minimizes performance and data-availability problems typically associated with remote access in distributed systems. Since Replication Server provides multiple copies of data, clients can rely on their own local data instead of remote, centralized databases. In addition, you can copy only the data you want to destination databases. Replication Server allows you to create a replication definition that identifies all or part of a table to replicate. You can then subscribe to only the rows you want. You can create a database replication definition that identifies the database objects—tables, functions, system procedures, transactions, and data definition language (DDL)—to replicate. You can also create a replication definition of a stored procedure (called function replication definition) to facilitate rapid replication of large amounts of data and to replicate updates from replicate databases back to the primary database. If your application requires it, you can consolidate or “roll up” replicated data from primary tables into a centralized database.
You can group replication definitions, both table replication definitions and functions replication definitions, in a publication and subscribe to them all at once. Publications allow you to organize subscriptions and then monitor them with a single command.
A Replication Agent—RepAgent for sites running Adaptive Server—transfers transaction information from a database to a Replication Server for distribution to replicate databases. Sybase also offers Replication Agent for Microsoft SQL Server, DB2, and Oracle. You can make Replication Agents for IMS and VSAM using the Sybase Replication Toolkit™ for MVS. RepAgent is an Adaptive Server thread; all other Replication Agents are separate processes.
Several models for replicating data in distributed systems exist in Replication Server. Consult the Replication Server Design Guide to help you determine which model best suits your application. The model that you choose determines how you set up your system.
Setting up a replication system based on your distribution model involves:
Creating tables to store primary and replicate data
Setting up routes and connections between Replication Servers and establishing permissions that control access to primary data
Creating replication definitions that identify the data you want replicated
Creating subscriptions from replicate databases to those replication definitions
See Chapter 2, “Replication Server Technical Overview” for a discussion of Replication Server components, concepts, and terminology. See Chapter 4, “Managing a Replication System” for a more detailed overview of setting up a Replication Server system.
