![]()
![]()
![]()
![]()
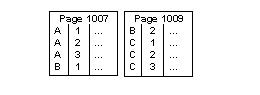
The table sales has a clustered index on store_id, customer_id. There are three stores (A, B, and C). Each store adds customer records in ascending numerical order. The table contains rows for the key values A,1; A,2; A,3; B,1; B,2; C,1; C,2; and C,3, and each page holds four rows, as shown in Figure 2-2.
Figure 2-2: Clustered table before inserts
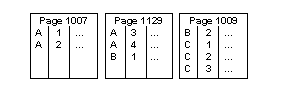
Using the normal page-splitting mechanism, inserting “A,4” results in allocating a new page and moving half of the rows to it, and inserting the new row in place, as shown in Figure 2-3.
Figure 2-3: Insert causes a page split
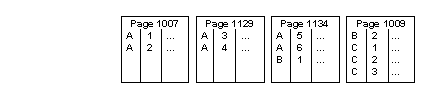
When “A,5” is inserted, no split is needed, but when “A,6” is inserted, another split takes place, as shown in Figure 2-4.
Figure 2-4: Another insert causes another page split
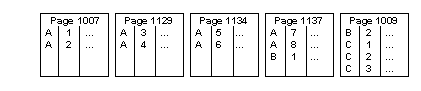
Adding “A,7” and “A,8” results in yet another page split, as shown in Figure 2-5.
Figure 2-5: Page splitting continues
For more information about data page splits, see Chapter 12, “How Indexes Work,” in the Performance and Tuning: Basics
