![]()
![]()
![]()
![]()
A high availability system includes the hardware and software necessary to limit the amount of downtime a system suffers. Sybase’s Failover is one piece of software in this high availability system. It provides the ability for the companion to withstand a single point of failure in the cluster.
A system that uses Sybase Failover includes only two machines. Each machine is one node of the high availability cluster. Each Adaptive Server is either a primary companion or secondary companion. Each companion performs the work during operations; the secondary companion takes over the workload when the primary companion fails or is brought down. The primary companion can be brought down for any number of reasons: scheduled maintenance, system failure, power outage, and so on. The event of the second server assuming another server’s workload is called failover. The event of moving the workload back to the original server once it is up and running again is called failback. Figure 1-1 describes a typical configuration consisting of two Adaptive Servers.
Included with the operating system is a high availability subsystem (for example, Sun Cluster for Sun, Microsoft Cluster Server for Windows NT, and so on) that detects and broadcasts to the cluster that part of the system is crashing or is being shut down for maintenance. When Adaptive Server goes down, the high availability subsystem tells the second machine to take over its workload. Any clients connected to the Adaptive Server going down are reconnected to the second Adaptive Server. Figure 1-1illustrates a high availability cluster is made up of two machines using Sybase’s Failover:
Figure 1-1: High availability system using Sybase’s Failover
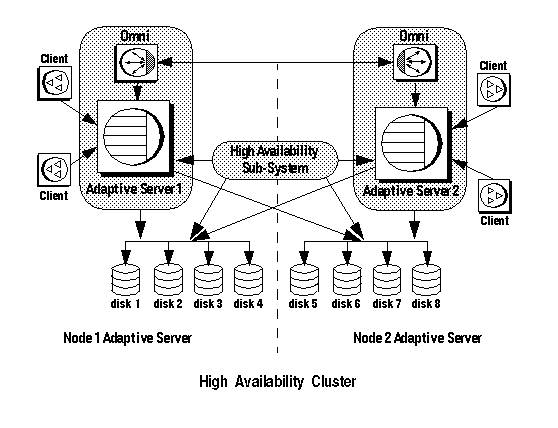
The machines in Figure 1-1 are configured so that each machine can read the other machine’s disks, although not at the same time (all the disks that are failed over should be shared disks).
For example, if Adaptive Server 1 is the primary companion, and it crashes, Adaptive Server 2, as the secondary companion, reads its disks (disks 1 – 4) and manages any databases on them until Adaptive Server 1 can be brought back online. Any clients connected to Adaptive Server 1 using the failover property, are connected automatically to Adaptive Server 2.
