Archive database access allows a database administrator to validate or selectively recover data from a database dump (an “archive”) by making the dump appear as if it were a traditional read-only database; this type of database is called an “archive database.”
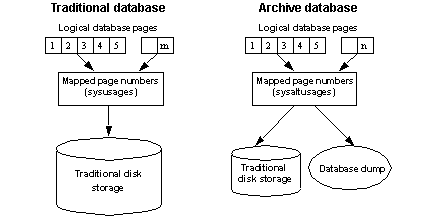
Unlike a traditional database, an archive database uses the actual database dump as its main disk storage device, with a minimum amount of traditional storage to represent new or modified pages that result from the recovery of the database dump. A database dump already contains the images of many (or even most) of the database pages, therefore, an archive database can be loaded without having to use Backup Server to transfer pages from the archive to traditional database storage. Consequently, the load is significantly faster than a traditional database.
Archive database access lets you perform a variety of operations directly on a database dump.
The amount of storage needed for a traditional database load must be equal to or greater than the size of the source database; the loading of the database dump using Backup Server involves copying pages from the database dump into the storage that has been set aside for the traditional database.
By contrast, you can create an archive database using a minimal amount of traditional disk storage. When you load an archive database, the pages residing in the database dump are not copied by the Backup Server. Instead, SAP ASE creates a map that represents a “logical-to-virtual” mapping of the pages within the archive. This significantly decreases the amount of time required to view the data in a database dump, and reduces the storage requirement for loading the dump.
An archive database does not have to be a complete copy of the original database. Depending on the optimization used when dumping the database using sp_dumpoptimize, an archive database may be fully populated (every page in the database is in the database dump), or partially populated (only allocated pages are stored in the database dump).
Because the database dump is presented as a read-only database, a database administrator can query it using familiar tools and techniques such as:
-
Running database consistency checks on the most recent copy of a dump made from a production database. These checks can be offloaded to a different server to avoid resource contention in the production environment. If resources are not a concern, the archive can be checked on the same server on which it was created. Verification on the archive provides the assurance needed prior to performing a restore operation.
-
If the integrity of a database dump is in question, loading it into an archive database can be a quick test for success, and therefore a good tool to identify the appropriate database dump that should be used to restore a traditional database.
-
Object-level restoration from the database dump. Lost data is recovered using select into to copy the to-be-restored rows from the table within the archive database. Perform the select into operation either directly in the server hosting the archive database, or by using Component Integration Services proxy tables if the archive database is available on a different server than that of the object requiring restoration.
In addition, transaction logs can be loaded into an archive database, thereby providing the assurance that the same load sequence can be applied when performing a restore operation. The figure below represents the differences between an archive database and a traditional database structure.