To improve performance of large ESP projects, separate the data into smaller chunks that are processed within their own partitions. Processing on multiple partitions in parallel can improve performance over processing in one large partition.
There are various ways to parallelize an ESP project.
1. Application-based Partitioning
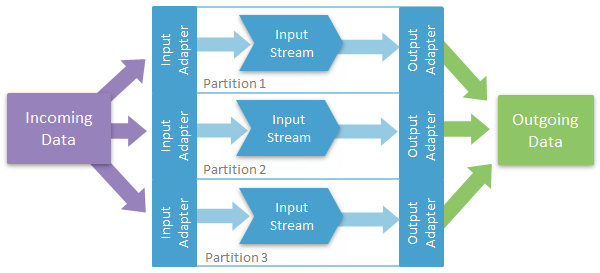
You can send all incoming data to each of the input adapters within your ESP project, and then attach each of these adapters to a stream or delta stream that filters a subset of the overall incoming data. The output adapters receive this data and output it to the external datasource.
- You can improve performance and process high volumes of data since having multiple streams processing subsets of the data divides the load on the processor.
- You also have the advantage of not having to create a custom adapter or do any custom coding aside from specifying the filtering.
- Can partition across cores, but is best suited for partitioning across machines.
- You have to duplicate the input data feeding into the input adapters.
2. Partitioning Using a Custom Adapter
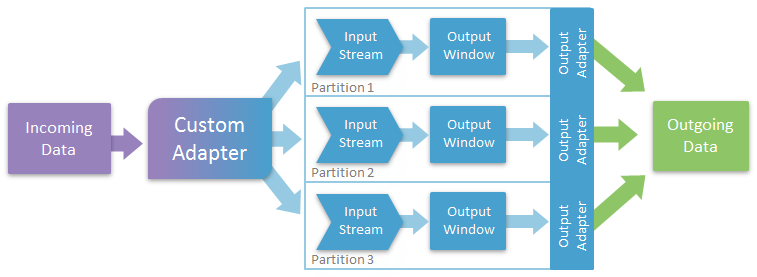
You can write a custom adapter to receive input data and publish it to various streams, delta streams, or windows on separate machines. These streams or windows would then process and send this data to separate output adapters which would then publish it to the end datasource. The custom adapter is responsible for partitioning the input data in this scenario.
- You can improve performance and process high volumes of data by filtering incoming data across multiple machines.
- You can customize your adapter to meet your partitioning requirements.
- You do not need to duplicate any data.
- Can partition across cores, but is best suited for partitioning across machines.
- Requires more effort in terms of coding because you have to write a custom adapter as you cannot currently partition the available adapters provided with Event Stream Processor.
3. Partitioning Using a SPLITTER Statement
You can use the CCL SPLITTER object to subdivide input data based on specific criteria, and then a UNION statement to consolidate the data before sending it to the output adapter.
- You have more flexibility in terms of the operations that you can perform on the streams resulting from the SPLITTER. For example, you first split the data, perform operations on the resulting streams, and then consolidate the data again.
- Can partition across cores.

Although the example in the illustration uses a single input adapter, you can use a SPLITTER when using multiple input adapters.
In both the cases, the number of parallel instances is limited to the throughput of the union and, when used, the SPLITTER. In addition, the number of parallel instances depends on the number of available CPUs.
General Guidelines
Hash partitioning uses hash functions to partition data. The hash function determines which partition to place a row into based on the column names you specify as keys. These do not have to be primary keys. Round-robin partitioning distributes data evenly across partitions without any regard to the values.
Choose a type based on the calculations you are performing on the input data. For example, round-robin is sufficient for stateless operations like simple filters, but not for aggregation as this would produce differing results. Hash partitioning is necessary for grouping records together, but grouping may not evenly distribute the data across instances.
When implementing the scenarios above, you can use round-robin or key-based partitioning. Round-robin partitioning provides the most even distribution across the multiple parallel instances, but is recommended only for projects limited to insert operations (that is, no updates or deletes). For projects using insert, update, and delete operations, key-based partitioning is preferable. Any update or delete operation on a record should occur on the same path where the record was inserted, and only key-based partitioning can guarantee this. However, key-based partitioning can distribute load unevenly if the HASH function is not applied correctly, which results in some partitions with a higher burden than others.
For more information on the SPLITTER and UNION statements, see the Programmers Reference Guide and refer to the splitter, Union, and RAP_splitter_examples provided in your Examples folder.