To maximize performance of large ESP projects, separate the data into smaller chunks that are processed within their own partitions. Processing on multiple partitions in parallel greatly improves performance over processing in one large partition.
There are two ways to parallelize a project in ESP. You can create multiple, parallel streams from input adapter all the way through to output adapter. Each stream handles a subset of the overall incoming data. The second method is to use the CCL SPLITTER object to subdivide data based on specific criteria, then a UNION statement to consolidate the data before sending it to the output adapter.
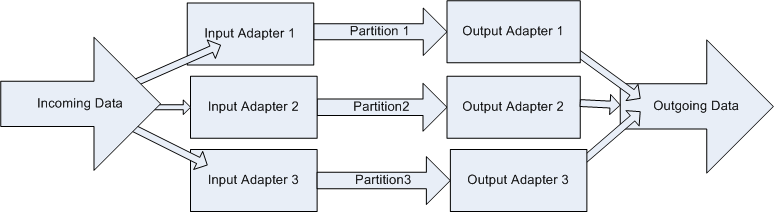
A simple, fully parallelized project may look similar to:
A simple project parallelized using the SPLITTER and UNION statements may look similar
to:

Although the example in the illustration uses a single input adapter, you can use a SPLITTER when using multiple input adapters.
In both the cases, the number of parallel paths is limited to the throughput of the union and, when used, the SPLITTER. In addition, the number of parallel computation paths depends on the number of available CPUs.
When dividing your project into parallel partitions, you can use round-robin or key-based partitioning. Round-robin partitioning provides the most even distribution across the multiple parallel paths, but is recommended only for projects limited to insert operations (that is, no updates or deletes). For projects using insert, update, and delete operations, key-based partitioning is preferable. Any update or delete operation on a record should occur on the same path where the record was inserted, and only key-based partitioning can guarantee this. Note, however, that key-based partitioning can distribute load unevenly, resulting in some partitions with a higher burden than others.
For more information on the SPLITTER and UNION statements, see the Programmers Reference and refer to the splitter, Union, and RAP_splitter_examples provided in your Examples folder.