The “my_interpolate” example is an OLAP-style UDAF that attempts to fill in any missing values in a sequence (where missing values are denoted by NULLs) by performing linear interpolation across any set of adjacent NULL values to the nearest non-NULL value in each direction.
my_interpolate declaration
If the input at a given row is not NULL, the result for that row is the same as the input value.
This table illustrates the effect of my_interpolate on a small set of input rows:
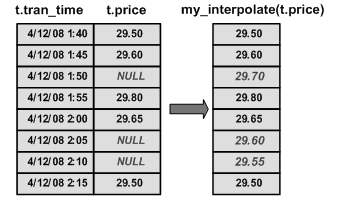
To operate at a sensible cost, my_interpolate must run using a fixed-width row-based window, but the user can set the width of the window based on the maximum number of adjacent NULL values he or she expects to see. This function takes a set of double-precision floating point values and produces a resulting set of doubles.
The resulting UDAF declaration looks like this:
CREATE AGGREGATE FUNCTION my_interpolate (IN arg1 DOUBLE) RETURNS DOUBLE OVER REQUIRED WINDOW FRAME REQUIRED RANGE NOT ALLOWED PRECEDING REQUIRED UNBOUNDED PRECEDING NOT ALLOWED FOLLOWING REQUIRED UNBOUNDED FOLLOWING NOT ALLOWED EXTERNAL NAME 'describe_my_interpolate@my_shared_lib'
OVER REQUIRED means that this function cannot be used as a simple aggregate (ON EMPTY INPUT, if used, is irrelevant).
WINDOW FRAME details specify that you must use a fixed width row-based window that extends both forward and backward from the current row when using this function. Because of these usage restrictions, my_interpolate is only usable as an OLAP-style aggregate with an OVER clause similar to:
SELECT t.x, my_interpolate(t.x) OVER (ORDER BY t.x ROWS BETWEEN 5 PRECEDING AND 5 FOLLOWING) AS x_with_gaps_filled, COUNT(*) FROM t GROUP BY t.x ORDER BY t.x
Within an OVER clause for my_interpolate, the precise number of preceding and following rows may vary, and optionally you can use a PARTITION BY; otherwise the rows must be similar to the example above given the usage restrictions in the declaration.