![]()
![]()
![]()
![]()
You use a cursor to retrieve rows from a query that has multiple rows in the result set. A cursor is a handle or an identifier for the SQL query result set and a position within that result set.
For an introduction to cursors, see Working with cursors.
To manage a cursor in embedded SQL
Declare a cursor for a particular SELECT statement, using the DECLARE statement.
Open the cursor using the OPEN statement.
Retrieve rows from the cursor one at a time using the FETCH statement.
Close the cursor, using the CLOSE statement.
Cursors in UltraLite applications are always opened using the WITH HOLD option. They are never closed automatically. You must explicitly close each cursor using the CLOSE statement.
The following is a simple example of cursor usage:
void print_employees( void )
{
int status;
EXEC SQL BEGIN DECLARE SECTION;
char name[50];
char sex;
char birthdate[15];
short int ind_birthdate;
EXEC SQL END DECLARE SECTION;
/* 1. Declare the cursor. */
EXEC SQL DECLARE C1 CURSOR FOR
SELECT emp_fname || ' ' || emp_lname,
sex, birth_date
FROM "DBA".employee
ORDER BY emp_fname, emp_lname;
/* 2. Open the cursor. */
EXEC SQL OPEN C1;
/* 3. Fetch each row from the cursor. */
for( ;; ) {
EXEC SQL FETCH C1 INTO :name, :sex,
:birthdate:ind_birthdate;
if( SQLCODE == SQLE_NOTFOUND ) {
break; /* no more rows */
} else if( SQLCODE < 0 ) {
break; /* the FETCH caused an error */
}
if( ind_birthdate < 0 ) {
strcpy( birthdate, "UNKNOWN" );
}
printf( "Name: %s Sex: %c Birthdate:
%s\n",name, sex, birthdate );
}
/* 4. Close the cursor. */
EXEC SQL CLOSE C1;
} |
For more information about the FETCH statement, see FETCH statement [ESQL] [SP].
A cursor is positioned in one of three places:
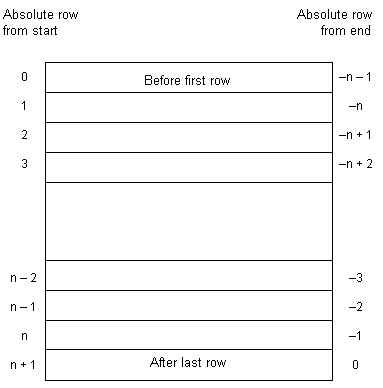
You control the order of rows in a cursor by including an ORDER BY clause in the SELECT statements that defines that cursor. If you omit this clause, the order of the rows is unpredictable.
If you don't explicitly define an order, the only guarantee is that fetching repeatedly will return each row in the result set once and only once before SQLE_NOTFOUND is returned.
When you open a cursor, it is positioned before the first row. The FETCH statement automatically advances the cursor position. An attempt to FETCH beyond the last row results in a SQLE_NOTFOUND error, which can be used as a convenient signal to complete sequential processing of the rows.
You can also reposition the cursor to an absolute position relative to the start or end of the query results, or you can move the cursor relative to the current position. There are special positioned versions of the UPDATE and DELETE statements that can be used to update or delete the row at the current position of the cursor. If the cursor is positioned before the first row or after the last row, a SQLE_NOTFOUND error is returned.
To avoid unpredictable results when using explicit positioning, you can include an ORDER BY clause in the SELECT statement that defines the cursor.
You can use the PUT statement to insert a row into a cursor.
After updating any information that is being accessed by an open cursor, it is best to fetch and display the rows again. If the cursor is being used to display a single row, FETCH RELATIVE 0 will re-fetch the current row. When the current row has been deleted, the next row will be fetched from the cursor (or SQLE_NOTFOUND is returned if there are no more rows).
When a temporary table is used for the cursor, inserted rows in the underlying tables do not appear at all until that cursor is closed and reopened. It is difficult for most programmers to detect whether or not a temporary table is involved in a SELECT statement without examining the code generated by the SQL preprocessor or by becoming knowledgeable about the conditions under which temporary tables are used. Temporary tables can usually be avoided by having an index on the columns used in the ORDER BY clause.
For more information about temporary tables, see Use work tables in query processing (use All-rows optimization goal).
Inserts, updates, and deletes to non-temporary tables may affect the cursor positioning. Because UltraLite materializes cursor rows one at a time (when temporary tables are not used), the data from a freshly inserted row (or the absence of data from a freshly deleted row) may affect subsequent FETCH operations. In the simple case where (parts of) rows are being selected from a single table, an inserted or updated row will appear in the result set for the cursor when it satisfies the selection criteria of the SELECT statement. Similarly, a freshly deleted row that previously contributed to the result set will no longer be within it.
| Send feedback about this page via email or DocCommentXchange | Copyright © 2008, iAnywhere Solutions, Inc. - SQL Anywhere 11.0.0 |