![]()
![]()
![]()
![]()
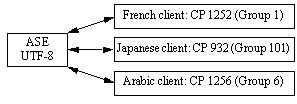
Adaptive Server also supports character set conversion between UTF-8 and any native character set that Sybase supports. In a Unicode system, since the server default character set is UTF-8, the client character set may be a native character set from any language group. Therefore, a Japanese client (group 101), a French client (Group 1), and an Arabic client (group 6) can all send and receive data from the same server. Data from each client is correctly converted as it passes between each client and the server.
Figure 8-2: Character set conversion in a Unicode system
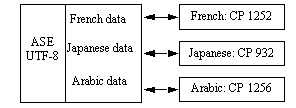
Note however, that each client can view data only in the language supported by its character set. Therefore, the Japanese client can view any Japanese data on the server, but it cannot view Arabic or French data. Likewise, the French client can view French or any other Western European language supported by its character set, but not Japanese or Arabic.
Figure 8-3: Viewing Unicode data
An additional character set, ASCII 7, is a subset of every character set, including Unicode, and is therefore compatible with all character sets in all language groups. If either the Adaptive Server or the client’s character set is ASCII 7, any 7-bit ASCII character can pass between the client and server unaltered and without conversion.
Sybase does not recommend that you configure a server for ASCII-7, but you can achieve the same benefits of compatibility by restricting each client to use only the first 128 characters of each native character set.
