Understand how to effectively use cache partitions.
 |
By default, the CDB for the MBO consists of a single partition. See Cache Partitions. |
|
Partitions are created when synchronization parameters are mapped to load arguments. All such load arguments use the partition key to identify the partition. If a synchronization parameter is not mapped to a load argument, a partition can still be defined by mapping the load argument to a personalization key. See Partition Membership. |
 |
To increase load parallelism, use multiple partitions. |
|
To reduce refresh latency, use multiple partitions. |
|
Use small partitions to retrieve “real-time” data when coupled with an on-demand policy and a cache interval of zero. |
|
Use partitions for user-specific data sets. |
|
Consider the partitioning by requester and device ID feature when appropriate. |
 |
Do not create overlapping partitions; that is, a member (MBO instance) should reside in only one partition to avoid bouncing. |
 |
Avoid partitions that are too coarse, which result in long refresh intervals. Avoid partitions that are too fine-grained, which require high overhead due to frequent EIS/Unwired Server interactions. |
Cache Partitions
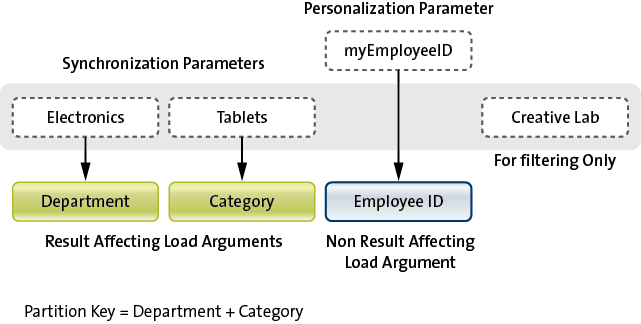
- A partition is the EIS result set returned by the read operation using a specific set of load arguments.
- Only the result-affecting load arguments form the partition key.
- Using non-result-affecting load arguments within the key causes multiple partitions to hold the same data.
Set of synchronization parameters mapped to load arguments = set of result affecting load arguments = partition key
Partitions are independent from one another, enabling the MBO cache to be refreshed and loaded in parallel under the right conditions. If the cache group policy requires partitions to be refreshed on access, multiple partitions may reduce contention, since refresh must be serialized. For example, you can model a catalog to be loaded or refreshed using a single partition. When the catalog is large, data retrieval is expensive and slow. However, if you can partition the catalog by categories, for example, tablet, desktop, laptop, and so on, it is reasonable to assume that each category can be loaded as needed and in parallel. Furthermore, the loading time for each partition is much faster than a full catalog load, reducing the wait time needed to retrieve a particular category.
Partition granularity is an important consideration during model development. Coarse-grained partitions incur long load/refresh times, whereas fine-grained partitions create overhead due to frequent EIS/Unwired Server interactions. The MBO developer must analyze the data to determine a reasonable partitioning scheme.
Partition Membership
Partitions cannot overlap. That is, a member can belong only to a single partition. Members belonging to multiple partitions cause a performance degradation, known as partition bouncing: when one partition refreshes, a multi-partition member bounces from an existing partition to the one currently refreshing. Besides the performance impact, the user who is downloading from the migrate-from partition may not see the member due to the bounce, depending on the cache group policy to which the MBO belongs.
An MBO instance is identified by its primary key which can only occur once within the table for the MBO cache. A partition is a unit of retrieval. If the instance retrieved through partition A is already in the cache but under partition B, the instance's partition membership is changed from B to A. It is important to understand that there is no data movement involved, just an update to the instance's membership information. As such, the migrated-from partition cache status remains valid. It is the responsibility of the developer to understand the ramification and adjust the cache group policy if needed.
Avoiding Partition Bouncing
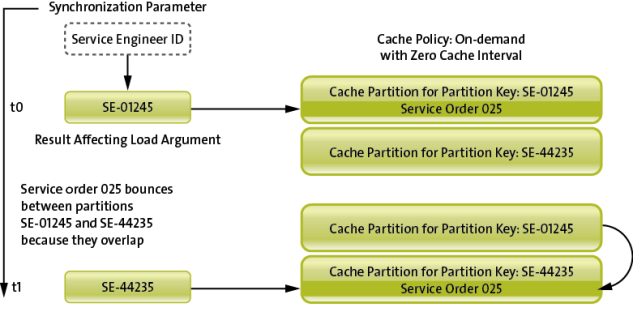
In the following use case, where a service order is purposely assigned to multiple users and using an On-demand policy with a zero cache interval, partition bouncing occurs when service engineer SE-44235 synchronizes at a later time. The service order is now on the devices of both engineers. However, consider the scenario where engineer SE-01245 also synchronizes at time t1. Service order 025 may no longer be in the partition identified by its ID, resulting in a deletion of the service order from the data store on the device when the client synchronizes.
To avoid partition bouncing in this example, augment the primary key of the approval MBO with the user identity. The result is that the same approval request is duplicated for each user to whom it is assigned. There is no partition bouncing at the expense of replication of data in the cache. From the partition's point of view, each member belongs to one partition because the cache module uses the primary key of the MBO to identify the instance and there can only be one such instance in the cache for that MBO.
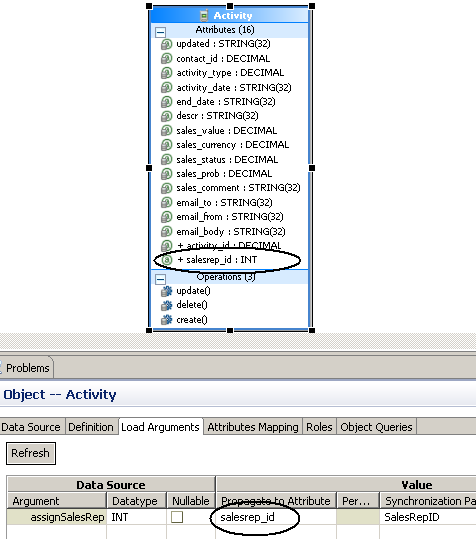
The diagrams below illustrate the primary key augmentation approach. The MBO can be assigned to multiple sales representatives in the EIS. MBO definition requests all activities for a particular sales representative using the SalesRepID as a synchronization parameter, which is mapped to the load argument that retrieves all activities for that user.
- Propagate the load argument as an additional attribute (salesrep_id)
to the Activity MBO.
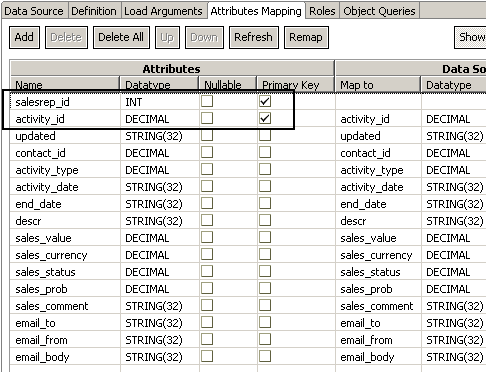
- Designate the primary key to be a composite key: activity_id and salesrep_id. This causes the cache module to treat the same activity as a different instance, avoiding bouncing at the expense of duplicating them in multiple partitions.
The previous example illustrates an MBO instance bouncing between partitions because they are assigned to multiple partitions at the same time. However, partition bouncing can also occur if load arguments to synchronization parameters are not carefully mapped. Consider this example:
Read Operation: getAllBooksByAuthor(Author, userKey) Synchronization Parameters: AuthorParameter, userIdParameter Mapping: AuthorParameter → Author, userIdParameter → userKey
- Jane Dole synchronizes using (“Crichton, Michael”, “JaneDole”) as parameters Cache invokes: getAllBooksByAuthor(“Crichton, Michael”, “JaneDole”)
- John Dole synchronizes using (“Crichton, Michael”, “JohnDole”) as parameters Cache invokes: getAllBooksByAuthor(“Crichton, Michael”, “JohnDole”)
- For invocation one, a partition identified by the keys “Crichton, Michael” + “JaneDole” is created.
- For invocation two, a second partition identified by the keys “Crichton, Michael” + “JohnDole” is created.
- All the data in the partition: “Crichton, Michael” + “JaneDole” moves to the partition: “Crichton, Michael” + “JohnDole”.
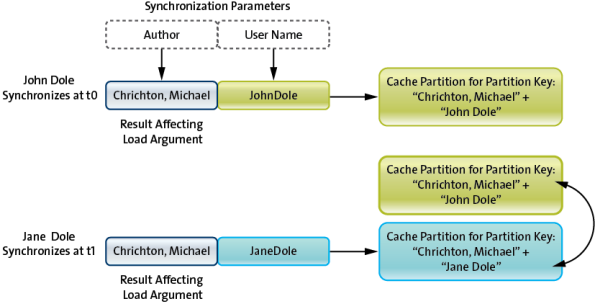
Cache Partition Overwrite
Partition overwrite is due to incorrect mapping of synchronization parameters and load arguments, and greatly hinders performance.
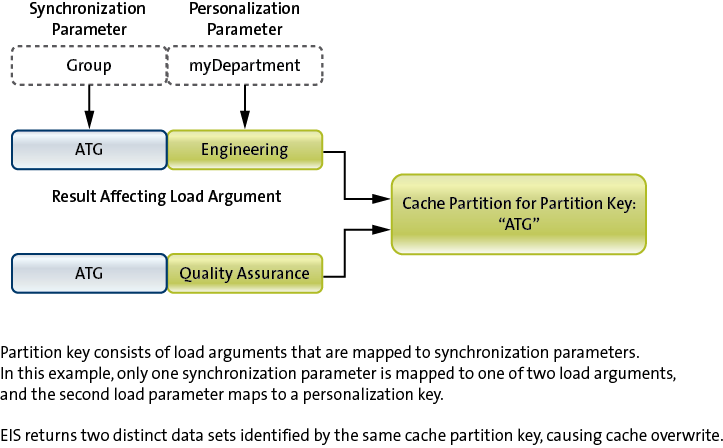
Read Operation: getEmployees(Group, Department) Synchronization Parameters: GroupParameter Mapping: GroupParameter → Group, myDepartment (personalization key) → Department
- Jane Dole synchronizes using (“ATG”) as parameters and her personalization key myDepartment Cache invokes: getEmployees(“ATG”, “Engineering”)
- Jane Dole synchronizes using (“ATG”) as parameters and his personalization key myDepartment Cache invokes: getEmployees(“ATG”, “Quality Assurance”)
- For invocation one, a partition identified by the key “ATG” will be created with employees from ATG Engineering department.
- For invocation two, the same partition identified by the key “ATG” is overwritten with employees from ATG Quality Assurance department.
- Not only is the cache constantly overwritten, depending on the cache group policy, one may actually get the wrong result.
User-Specific Partitions
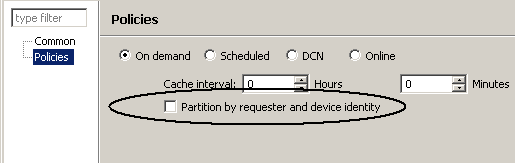
Partitions are often used to hold user-specific data, for example, service tickets that are assigned to a field engineer. In this case, the result-affecting load arguments consist of user-specific identities. Unwired Server provides a special user partition feature that can be enabled by selecting the "partition by requester and device ID" option. The EIS read operation must provide load arguments that can be mapped to both requester and device identities. The result is that each user has his or her own partition on a particular device. That is, one user can have two partitions if he or she uses two devices for the same mobile application. The CDB manages partitioning of the data returned by the EIS. The primary key of the returned instance is augmented with the requester and device identities. Even if the same instance is returned for multiple partitions, no bouncing occurs as it is duplicated.
Developers can easily define their own user-specific partition by providing appropriate user identities as load arguments to the EIS read operation.
Partitions and Real-Time Data
For some mobile applications, current data from the EIS is required upon synchronization. This implies that Unwired Server must retrieve data from EIS to satisfy the synchronization. If the amount of data for each retrieval is large, it is very expensive. Fortunately, real-time data is usually relatively small so you can employ a partition to represent that slice of data. It is important that the MBO is in its own synchronization and cache groups, which allows a user to retrieve only the data required from the EIS and download it to the device upon synchronization. This use case requires an on-demand cache group policy with zero cache interval.