You can often dramatically improve the performance of large Sybase CEP applications by distributing the queries in your Sybase CEP Engine project into several sets of data and processing each set on a separate machine. This feature is called Parallel Queries, or parallel processing.
For example, consider a stock exchange that calculates daily averages for 5,000 stocks. If time is not an issue, all 5,000 stocks can be processed by a single project on one computer. However, performance will be greatly enhanced if the 5,000 stocks are distributed across 5,000 computers, with each computer calculating the average for a single stock. In this example, you might route prices for each stock to the appropriate computer as they arrive, then calculate the average for each stock and gather the final data once more on a single computer.
Here is a more realistic example. Suppose that you have five computers processing 5,000 stocks. You allocate 1,000 stocks to each computer. Arriving data is routed to the appropriate computer to calculate the daily average and to perform other calculations. In this scenario, the average calculation would be performed approximately five times faster than would be the case with only one computer doing all the work.
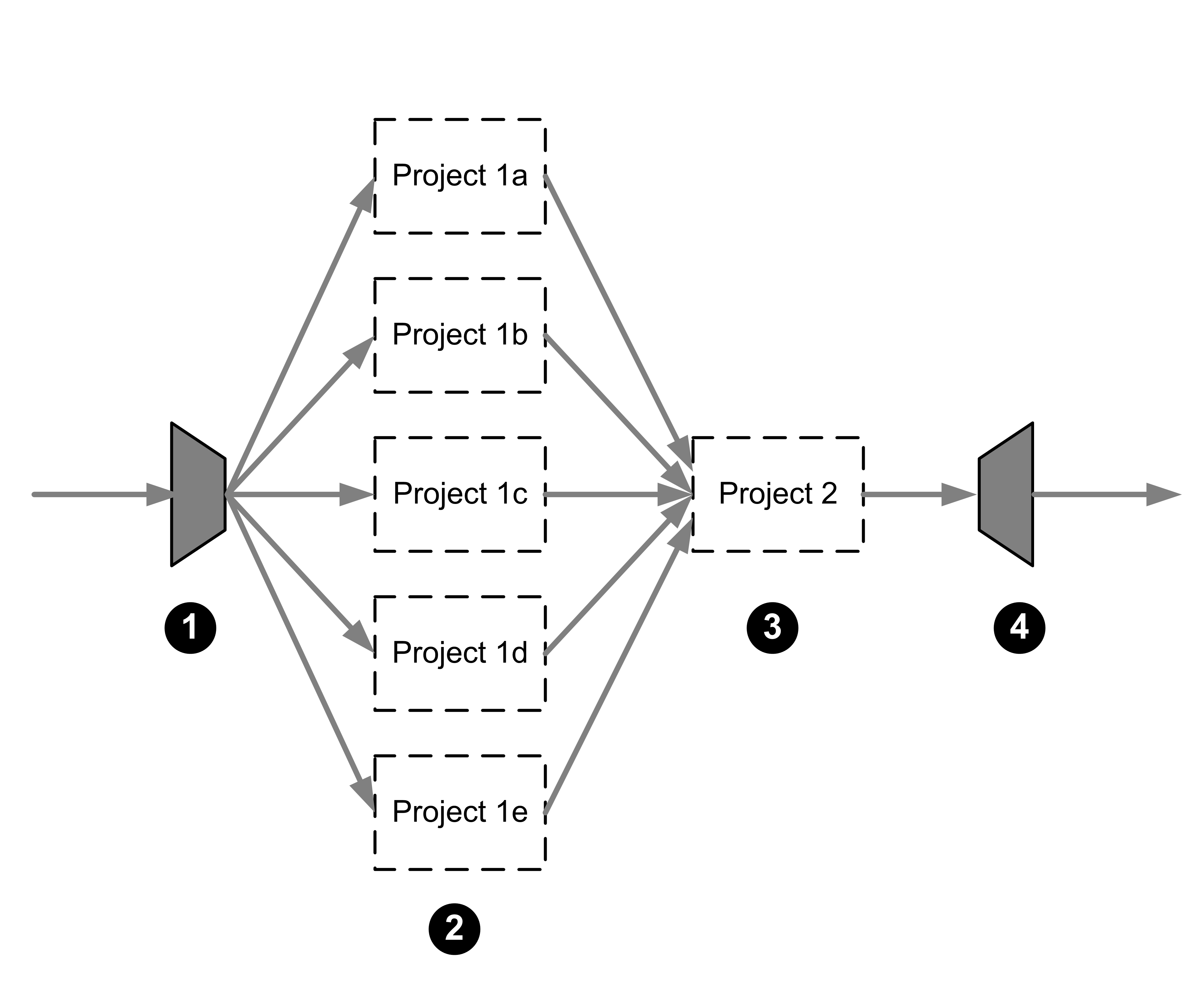
Here is an illustration of an application using parallel queries, with an explanation of the role played by each component:
-
A user-defined out-of-process adapter splits the incoming data into multiple streams and then sends each stream to one of the project instances.
-
Five identical project instances process the data in parallel.
-
When the processing is finished, each query processor project instance sends its data to another project, which is responsible for merging the data back into a single stream. This project may also include other queries that process the merged data.
-
Sybase CEP Engine then sends the merged data to an external destination through an output adapter.