![]()
![]()
![]()
![]()
When a computer system fails, the databases, metadata, and user connections are moved to a secondary server so that users can still access data. This is known as failover.
With Adaptive Server®, you set up a high availability cluster that is configured for failover. There are three sequential steps for failover:
System failover – the primary node fails over to the secondary node.
Companion failover – the primary companion fails over to the secondary node.
Connection failover – connection with the failover property fails over to the secondary companion.
Steps 2 and 3 are described below. See your high availability system documentation for a description of step 1.
During fail over, a secondary server detects the primary failure through the operating system’s high availability system and initiates the failover mechanism, which:
Performs a disk reinit to remap the master device path name to its local drive. disk reinit does not disturb the contents of the master device.
Mounts the master database, recovers it, and brings it online.
Maps each of the devices listed in the primary companion’s sysdevices to the secondary companion’s sysdevices and performs a disk reinit on the disks.
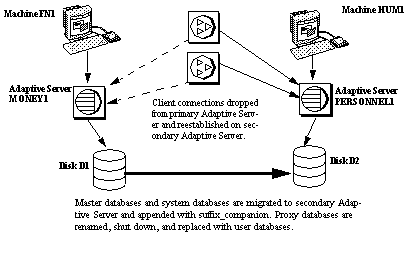
Mounts all the primary companion databases on the secondary companion. The secondary companion brings all databases online, after performing recovery from the logs. tempdb and model are not mounted. Proxy databases are mounted with the name comp_dbid_dbname.
Each database the secondary companion mounts has the suffix _companion appended to its name (for example, the master database becomes master_companion, sybsystemprocs becomes sybsystemprocs_companion, and so on). The secondary Adaptive Server adds this suffix to ensure the unique identity of the databases currently on its system. The user databases do not have the _companion suffix appended to their name; they are guaranteed to be unique.
User connections with the failover property and clients using the CS_FAILOVER property are retained and reestablished on the secondary companion. Uncommitted transactions must be resubmitted.
Once the secondary companion receives the failover message from the high availability system, no new transactions are started on the clients connected to the primary companion. Any transactions that are not complete at the time of fail over are rolled back. After fail over is complete, clients or users must resubmit rolled-back transactions.
