![]()
![]()
![]()
![]()
You can use SQL windowing extensions to configure the bounds of a window, and the partitioning and ordering of the input rows. Logically, as part of the semantics of computing the result of a query specification, partitions are created after the groups defined by the GROUP BY clause are created, but before the evaluation of the final SELECT list and the query's ORDER BY clause. So, the order of evaluation of the clauses within a SQL statement is:
FROM
WHERE
GROUP BY
HAVING
WINDOW
DISTINCT
ORDER BY
When forming your query, the impact of the order of evaluation should be considered. For example, you cannot have a predicate on an expression referencing a window function in the same SELECT query block. However, by putting the query block in a derived table, you can specify a predicate on the derived table. The following query fails with a message indicating that the failure was the result of a predicate being specified on a window function:
SELECT DepartmentID, Surname, StartDate, Salary,
SUM( Salary ) OVER ( PARTITION BY DepartmentID
ORDER BY StartDate
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS "Sum_Salary"
FROM Employees
WHERE State IN ( 'CA', 'UT', 'NY', 'AZ' )
AND DepartmentID IN ( '100', '200' )
GROUP BY DepartmentID, Surname, StartDate, Salary
HAVING Salary > 0 AND "Sum_Salary" > 200
ORDER BY DepartmentID, StartDate; |
Use a derived table (DT) and specify a predicate on it to achieve the results you want:
SELECT * FROM ( SELECT DepartmentID, Surname, StartDate, Salary,
SUM( Salary ) OVER ( PARTITION BY DepartmentID
ORDER BY StartDate
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS "Sum_Salary"
FROM Employees
WHERE State IN ( 'CA', 'UT', 'NY', 'AZ' )
AND DepartmentID IN ( '100', '200' )
GROUP BY DepartmentID, Surname, StartDate, Salary
HAVING Salary > 0
ORDER BY DepartmentID, StartDate ) AS DT
WHERE DT.Sum_Salary > 200; |
Because window partitioning follows a GROUP BY operator, the result of any aggregate function, such as SUM, AVG, or VARIANCE, is available to the computation done for a partition. So, windows provide another opportunity to perform grouping and ordering operations in addition to a query's GROUP BY and ORDER BY clauses.
When you define the window over which a window function operates, you specify one or more of the following:
Partitioning (PARTITION BY clause) The PARTITION BY clause defines how the input rows are grouped. If omitted, the entire input is treated as a single partition. A partition can be one, several, or all input rows, depending on what you specify. Data from two partitions is never mixed. That is, when a window reaches the boundary between two partitions, it completes processing the data in one partition, before beginning on the data in the next partition. This means that the window size may vary at the beginning and end of a partition, depending on how the bounds are defined for the window.
Ordering (ORDER BY clause) The ORDER BY clause defines how the input rows are ordered, prior to being processed by the window function. The ORDER BY clause is required only if you are specifying the bounds using a RANGE clause, or if a ranking function references the window. Otherwise, the ORDER BY clause is optional. If omitted, the database server processes the input rows in the most efficient manner.
Bounds (RANGE and ROWS clauses) The current row provides the reference point for determining the start and end rows of a window. You can use the RANGE and ROWS clauses of the window definition to set these bounds. RANGE defines the window in terms of a range of data values offset from the value in the current row. So, if you specify RANGE, you must also specify an ORDER BY clause since range calculations require that the data be ordered.
ROWS defines the window in terms of the number of rows offset from the current row.
Since RANGE defines a set of rows in terms of a range of data values, the rows included in a RANGE window can include rows beyond the current row. This is different from how ROWS is handled. The following diagram illustrates the difference between the ROWS and RANGE clauses:
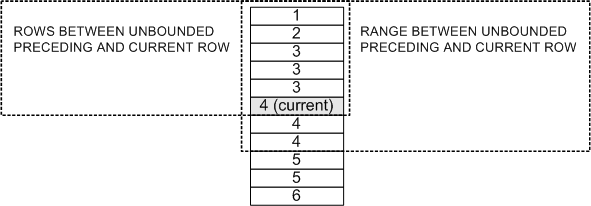
If the window specification contains an ORDER BY clause, it is equivalent to specifying RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
If the window specification does not contain an ORDER BY clause, it is equivalent to specifying ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
The following table contains some example window bounds and description of the rows they contain:
| Specification | Meaning |
|---|---|
|
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW |
Start at the beginning of the partition, and end with the current row. Use this when computing cumulative results, such as cumulative sums. |
|
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING |
Use all rows in the partition. Use this when you want the value of an aggregate function to be identical for each row of a partition. |
|
ROWS BETWEEN x PRECEDING AND y FOLLOWING |
Create a fixed-size moving window of rows starting at a distance of x from current row and ending at a distance of y from current row (inclusive). Use this example when you want to calculate a moving average, or when you want to compute differences in values between adjacent rows. With a moving window of more than one row, NULLs occur when computing the first and last row in the partition. This occurs because when the current row is either the very first or very last row of the partition, there are no preceding or following (respectively) rows to use in the computation. Therefore, NULL values are used instead. |
|
ROWS BETWEEN CURRENT ROW AND CURRENT ROW |
A window of one row; the current row. |
|
RANGE BETWEEN 5 PRECEDING AND 5 FOLLOWING |
Create a window that is based on values in the rows. For example, suppose that for the current row, the column specified in
the ORDER BY clause contains the value 10. If you specify the window size to be RANGE BETWEEN 5 PRECEDING AND 5 FOLLOWING, you are specifying the size of the window to be as large as required to ensure that the first row contains a 5 in the column,
and the last row in the window contains a 15 in the column. As the window moves down the partition, the size of the window
may grow or shrink according to the size required to fulfill the range specification.
|
Make your window specification as explicit as possible. Otherwise, the defaults may not return the results you expect.
Use the RANGE clause to avoid problems caused by gaps in the input to a window function when the set of values is not continuous. When a window bounds are set using a RANGE clause, the database server automatically handles adjacent rows and rows with duplicate values.
RANGE uses unsigned integer values. Truncation of the range expression can occur depending on the domain of the ORDER BY expression and the domain of the value specified in the RANGE clause.
Do not specify window bounds when using a ranking or a row-numbering function.
| Discuss this page in DocCommentXchange. Send feedback about this page using email. |
Copyright © 2009, iAnywhere Solutions, Inc. - SQL Anywhere 11.0.1 |